Table of Contents
List of Figures
Abstract
Abstract
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. The system is centrally managed and allows for intelligent dynamic management. It uses a simple extensible data model that allows for online analytic applications.
Flume is a distributed, reliable, and available service for efficiently moving large amounts of data soon after the data is produced. This release provides a scalable conduit to move data around a cluster as well as reliable logging.
The primary use case for Flume is as a logging system that gathers a set of log files on every machine in a cluster and aggregates them to a centralized persistent store such as the Hadoop Distributed File System (HDFS).
The system was designed with these four key goals in mind:
This section provides a high-level overview of Flume’s architecture and describes how the four design goals are achieved.
Flume’s architecture is simple, robust, and flexible. The main abstraction in Flume is a stream-oriented data flow. A data flow describes the way a single stream of data is transferred and processed from its point of generation to its eventual destination. Data flows are composed of logical nodes that can transform or aggregate the events they receive. Logical nodes are wired together in chains to form a data flow. The way in which they are wired is called the logical node’s configuration.
Controlling all this is the Flume Master, which is a separate service with knowledge of all the physical and logical nodes in a Flume installation. The Master assigns configurations to logical nodes, and is responsible for communicating configuration updates by the user to all logical nodes. In turn, the logical nodes periodically contact the master so they can share monitoring information and check for updates to their configuration.
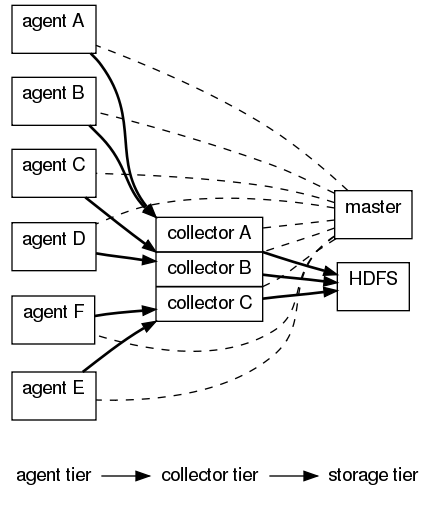
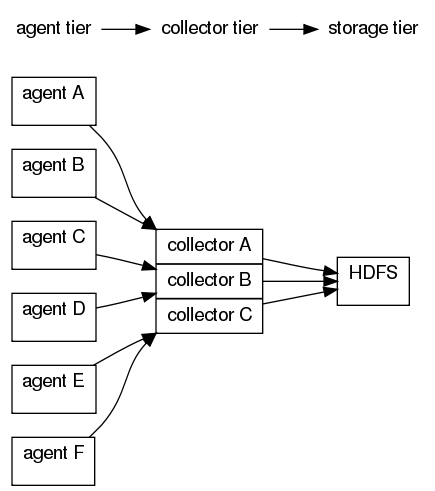
The graph above shows a typical deployment of Flume that collects log data from a set of application servers. The deployment consists of a number of logical nodes, arranged into three tiers. The first tier is the agent tier. Agent nodes are typically installed on the machines that generate the logs and are your data’s initial point of contact with Flume. They forward data to the next tier of collector nodes, which aggregate the separate data flows and forward them to the final storage tier.
For example, the agents could be machines listening for syslog data
or monitoring the logs of a service such as a web server or the Hadoop
JobTracker. The agents produce streams of data that are sent to the
collectors; the collectors then aggregate the streams into larger
streams which can be written efficiently to a storage tier such as
HDFS.
Logical nodes are a very flexible abstraction. Every logical node has just two components - a source and a sink. The source tells a logical node where to collect data, and the sink tells it where to send the data. The only difference between two logical nodes is how the source and sink are configured. Both source and sink can additionally be configured with decorators which perform some simple processing on data as it passes through. In the previous example, the collector and the agents are running the same node software. The Master assigns a configuration to each logical node at run-time - all components of a node’s configuration are instantiated dynamically at run-time, and therefore configurations can be changed many times throughout the lifetime of a Flume service without having to restart any Java processes or log into the machines themselves. In fact, logical nodes themselves can be created and deleted dynamically.
The source, sink, and optional decorators are a powerful set of primitives. Flume uses this architecture to provide per-flow data properties (for example durability guarantees, compression, or batching), or to compute event metadata, or even generate new events that are inserted into data flow. A logical node can also send data downstream to several logical nodes. This allows for multiple flows and each subflow can potentially be configured differently. For example, it’s possible to have one flow be a collection path, delivering data reliably to a persistent store, while another branch computes lightweight analytics to be delivered to an alerting system.
Reliability, the ability to continue delivering events in the face of failures without losing data, is a vital feature of Flume. Large distributed systems can and do suffer partial failures in many ways - physical hardware can fail, resources such as network bandwidth or memory can become scarce, or software can crash or run slowly. Flume emphasizes fault-tolerance as a core design principle and keeps running and collecting data even when many components have failed.
Flume can guarantee that all data received by an agent node will eventually make it to the collector at the end of its flow as long as the agent node keeps running. That is, data can be reliably delivered to its eventual destination.
However, reliable delivery can be very resource intensive and is often a stronger guarantee than some data sources require. Therefore, Flume allows the user to specify, on a per-flow basis, the level of reliability required. There are three supported reliability levels:
The end-to-end reliability level guarantees that once Flume accepts an event, that event will make it to the endpoint - as long as the agent that accepted the event remains live long enough. The first thing the agent does in this setting is write the event to disk in a 'write-ahead log' (WAL) so that, if the agent crashes and restarts, knowledge of the event is not lost. After the event has successfully made its way to the end of its flow, an acknowledgment is sent back to the originating agent so that it knows it no longer needs to store the event on disk. This reliability level can withstand any number of failures downstream of the initial agent.
The store on failure reliability level causes nodes to only require an acknowledgement from the node one hop downstream. If the sending node detects a failure, it will store data on its local disk until the downstream node is repaired, or an alternate downstream destination can be selected. While this is effective, data can be lost if a compound or silent failure occurs.
The best-effort reliability level sends data to the next hop with no attempts to confirm or retry delivery. If nodes fail, any data that they were in the process of transmitting or receiving can be lost. This is the weakest reliability level, but also the most lightweight.
Scalability is the ability to increase system performance linearly - or better - by adding more resources to the system. Flume’s goal is horizontal scalability — the ability to incrementally add more machines to the system to increase throughput. A key performance measure in Flume is the number or size of events entering the system and being delivered. When load increases, it is simple to add more resources to the system in the form of more machines to handle the increased load.
As seen in the preceding example installation, there are three separate components of Flume that require different approaches to scalability: the collector tier, the master, and the storage tier.
The collector tier needs to be able to scale in order to handle large volumes of data coming from large numbers of agent nodes. This workload is write heavy, partitionable, and thus parallelizable. By adding more machines to the collector tier, you can increase the number of agents and the maximum available throughput of the system.
An individual collector can usually handle many agents (up to hundreds) because each individual agent often produces only small amounts of log data compared to the full bandwidth available to the collector. Therefore, Flume balances flows from agents across different collectors. (One flow from an agent will talk to the same collector.) Flume uses a randomized algorithm to evenly assign lists of collectors to flows. This automatically spreads the load, and also keeps the load spread in the case where a collector fails.
As the number of nodes in the system increases, the volume of traffic on the control path to and from the Flume Master may become a bottleneck. The Flume Master also supports horizontal scaling by adding more machines - although just a small number of commodity servers can serve a large installation of nodes. The state of the Flume Master is kept synchronized and fully replicated, which ensures that it is both fault tolerant and highly scalable.
Finally, Flume can only write data through a flow at the rate that the final destinations can accept. Although Flume is able to buffer data inside a flow to smooth out high-volume bursts, the output rate needs to be equal on average to the input rate to avoid log jams. Thus, writing to a scalable storage tier is advisable. For example, HDFS has been shown to scale to thousands of machines and can handle many petabytes of data.
Manageability is the ability to control data flows, monitor nodes, modify settings, and control outputs of a large system. Manually managing the data flow from the sources to the end point is tedious, error prone, and a major pain point. With the potential to have thousands of log-generating applications and services, it’s important to have a centralized management point to monitor and change data flows, and the ability to dynamically handle different conditions or problems.
The Flume Master is the point where global state such as the data flows can be managed. Via the Flume Master, users can monitor flows and reconfigure them on the fly. The Flume Master has the information required to automatically respond to system changes such as load imbalances, partial failures, or newly provisioned hardware.
You can dynamically reconfigure nodes by using the Flume Master. Although this guide describes examples of traditional three-tier deployments, the flexibility of the nodes allow for arbitrary node topologies. You can reconfigure nodes by using small scripts written in a flexible dataflow specification language, which can be submitted via the Flume Master interface.
You can administer the Flume Master by using either of two interfaces: a web interface or the scriptable Flume command shell. The web interface provides interactive updates of the system’s state. The shell enables administration via manually crafted scripts or machine-generated scripts.
Extensibility is the ability to add new functionality to a system. For example, you can extend Flume by adding connectors to existing storage layers or data platforms. This is made possible by simple interfaces, separation of functional concerns into simple composable pieces, a flow specification language, and a simple but flexible data model.
Flume provides many common input and output connectors. When new input connectors (sources) are added, extra metadata fields specific to that source can be attached to each event it produces. Flume reuses the common components that provide particular reliability and resource usage properties. Some general sources include files from the file system, syslog and syslog-ng emulation, or the standard output of a process. More specific sources such as IRC channels and Twitter streams can also be added. Similarly, there are many output destinations for events. Although HDFS is the primary output destination, events can be sent to local files, or to monitoring and alerting applications such as Ganglia or communication channels such as IRC.
To enable easy integration with HDFS, MapReduce, and Hive, Flume provides simple mechanisms for output file management and output format management. Data gathered by Flume can be processed easily with Hadoop and Hive.
The preceding Introduction section describes the high level goals and features of Flume. The following sections of this guide describe how to set up and use Flume:
In this section, you will learn how to get a single Flume node running and transmitting data. You will also learn about some data sources, and how to configure Flume flows on a per-node basis.
Each logical node consists of a event-producing source and an event- consuming sink. Nodes pull data from their sources, and push data out through their sink.
![[Note]](images/note.png) | Note |
|---|---|
This section assumes that the Flume node and Flume Master are running in the foreground and not as daemons. You can stop the daemons by using /etc/ init.d/flume-master stop and /etc/init.d/flume-node stop. |
Start by getting a Flume node running that echoes data written to standard
input from the console back out to the console on stdout. You do this by using
the dump command.
$ flume dump console
![[Tip]](images/tip.png) | Tip |
|---|---|
The Flume program has the general form |
| Tip |
|---|---|
The example above uses the |
| Note |
|---|---|
Some flume configurations by default write to local disk.
Initially the default is /tmp/flume. This is good for initial
testing but for production environments the |
| Note |
|---|---|
If the node refuses to run and exits with this message,
|
You have started a Flume node where console is the source of incoming data.
When you run it, you should see some logging messages displayed to the
console. For now, you can ignore messages about Masters, back-off and failed
connections (these are explained in later sections). When you type at the
console and press a new line, you should see a new log entry line appear
showing the data that you typed. If you entered This is a test, it should
look similar to this:
hostname [INFO Thu Nov 19 08:37:13 PST 2009] This is a test
To exit the program, press ^C.
| Note |
|---|---|
Some sources do not automatically exit and require a manual ^C to exit. |
You can also specify other sources of events. For example, if you want a text file where each line represents a new event, run the following command.
$ flume dump 'text("/etc/services")'This command reads the file, and then outputs each line as a new event.
| Note |
|---|---|
The default console output escapes special characters with Java-style escape sequences. Characters such as " and \ are prefaced with an extra \. |
| Note |
|---|---|
You can try this command with other files such as |
If you want to tail a file instead of just reading it, specify another source
by using tail instead of text.
$ flume dump 'tail("testfile")'This command pipes data from the file into Flume and then out to the console.
This message appears: "File testfile does not currently exist, waiting for file to appear".
In another terminal, you can create and write data to the file:
$ echo Hello world! >> testfile
New data should appear.
When you delete the file:
$ rm testfile
The tail sink detects this. If you then recreate the file, the tail
source detects the new file and follows it:
$ echo Hello world again! >> testfile
You should see your new message appear in the Flume node console.
You can also use the multitail source to follow multiple files by file name:
$ flume dump 'multitail("test1", "test2")'And send it data coming from the two different files:
$ echo Hello world test1! >> test1 $ echo Hello world test2! >> test2
The tail source by default assumes \n as a delimiter, and excludes
the delimiter from events. There are optional line delimiter
arguments that allow you to specify arbitrary regular expressions as
delimiters and to specify if the delimiter should be part of the
prev ious event, next event, or exclude d.
Here are some examples and scenarios to illustrate:
The following example tails a file that requires two or more consecutive new lines to be considered a delimiter. The newlines are excluded from the events.
tail("file", delim="\n\n+", delimMode="exclude")This example tails a file and uses </a> as a delimiter, and appends
the delimiter to the previous event. This could serve as a
quick-and-dirty xml record splitter.
tail("file", delim="</a>", delimMode="prev")Finally, this example tails a file and uses the regex "\n\d\d\d\d" as a delimiter and appends the delimiter to the next event. This could be used to gather lines from a stack dump in a log file that starts with four digits (like a year from a date stamp).
tail("file", delim="\\n\\d\\d\\d\\d", delimMode="next")Here’s one more example where you use the synth sources to generate events:
$ flume dump 'asciisynth(20,30)'
You should get 20 events, each with 30 random ASCII bytes.
As with files, you can also accept data from well known wire formats such as syslog. For example, you can start a traditional syslog-like UDP server listening on port 5140 (the normal syslog UDP port is the privileged port 514) by running this command:
$ flume dump 'syslogUdp(5140)'
You can feed the source data by using netcat to send syslog formatted data as shown in the example below:
$ echo "hello via syslog" | nc -u localhost 5140
| Tip |
|---|---|
You may need to press ^C to exit this command. |
| Note |
|---|---|
The extra |
Similarly, you can set up a syslog-ng compatible source that listens on TCP port 5140 (the normal syslog-ng TCP port is the privileged port 514):
$ flume dump 'syslogTcp(5140)'
And send it data:
$ echo "
| Tip |
|---|---|
You may need to press ^C to exit this command. |
Syslog backwards-compatibility allows data normally created from syslog, rsyslog, or syslog-ng to be sent to and processed by Flume.
This section describes a number of sources of data that Flume can interoperate with. Before going any further, it will be helpful for you to understand what Flume is actually sending and processing internally.
Flume internally converts every external source of data into a stream of events. Events are Flume’s unit of data and are a simple and flexible representation. An event is composed of a body and metadata. The event body is a string of bytes representing the content of an event. For example, a line in a log file is represented as an event whose body was the actual byte representation of that line. The event metadata is a table of key / value pairs that capture some detail about the event, such as the time it was created or the name of the machine on which it originated. This table can be appended as an event travels along a Flume flow, and the table can be read to control the operation of individual components of that flow. For example, the machine name attached to an event can be used to control the output path where the event is written at the end of the flow.
An event’s body can be up to 32KB long - although this limit can be controlled via a system property, it is recommended that it is not changed in order to preserve performance.
In this section, you learned how to use Flume’s dump command to print data
from a variety of different input sources to the console. You also learned
about the event, the fundamental unit of data transfer in Flume.
The following table summarizes the sources described in this section.
Flume Event
console
text("filename")
tail("filename")
tail -F. One line is one event.
Stays open for more data and follows filename if file rotated.
multitail("file1"[, "file2"[, …]])
tail source but follows
multiple files.
asciisynth(msg_count,msg_size)
syslogUdp(port)
syslogTcp(port)
Flume is intended to be run as a distributed system with processes spread out across many machines. It can also be run as several processes on a single machine, which is called “pseudo-distributed” mode. This mode is useful for debugging Flume data flows and getting a better idea of how Flume components interact.
The previous section described a Flume node and introduced the concept of Flume sources. This section introduces some new concepts required for a distributed setup: the Flume master server, the specification of sources and sinks, and connecting multiple Flume nodes.
There are two kinds of processes in the system: the Flume master and the Flume node. The Flume Master is the central management point and controls the data flows of the nodes. It is the single logical entity that holds global state data and controls the Flume node data flows and monitors Flume nodes. Flume nodes serve as the data path for streams of events. They can be the sources, conduits, and consumers of event data. The nodes periodically contact the Master to transmit a heartbeat and to get their data flow configuration.
In order to get a distributed Flume system working, you must start a single Flume Master and some Flume nodes that interact with the Master. You’ll start with a Master and one Flume node and then expand.
The Master can be manually started by executing the following command:
$ flume master
After the Master is started, you can access it by pointing a web browser to http://localhost:35871/. This web page displays the status of all Flume nodes that have contacted the Master, and shows each node’s currently assigned configuration. When you start this up without Flume nodes running, the status and configuration tables will be empty.

The web page contains four tables — the Node status table, the Node configuration table, the Physical/Logical Node mapping table, and a Command history table. The information in these tables represent the current global state of the Flume system.
The Master’s Node status table contains the names of all of the Flume Nodes
talking to the Master, their current configuration version (initially "none"),
their status (such as IDLE), and when it last reported to the Master. The
name of each Flume node should be the same as running hostname from Unix
prompt.
The Master’s Node configuration table contains the logical name of a node, the configuration version assigned to it, and a specification of its sources and its sinks. Initially, this table is empty, but after you change values you can view this web page to see the updates. There are two sets of columns - - the user entered version/source/sink, and translated version/source/sink. A later section of this guide describes translated configs.
The Master’s Physical/Logical Node mapping table contains the mapping of logical nodes to their physical nodes.
The Master’s Command history table contains the state of commands. In general, commands modify the Master’s global state. Commands are processed serially on a Master and are assigned a unique command ID number. Each command has a state (for example, SUCCEEDED, FAILED, or PENDING), a command line, and a message which often contains information about its execution attempt.
To start a Flume node, invoke the following command in another terminal.
$ flume node_nowatch
| Note |
|---|---|
Normally, you start a node using |
To check whether a Flume node is up, point your browser to the Flume Node status page at http://localhost:35862/. Each node displays its own data on a single table that includes diagnostics and metrics data about the node, its data flows, and the system metrics about the machine it is running on. If you have multiple instances of the flume node program running on a machine, it will automatically increment the port number and attempt to bind to the next port (35863, 35864, etc) and log the eventually selected port.
If the node is up, you should also refresh the Master’s status page (http://
localhost:35871) to make sure that the node has contacted the Master. You
brought up one node (assume the node is named host), so you should have
one node listed in the Master’s node status table, and an entry in the logical
node mapping table that links the host logical node to the host
physical nodes.
Requiring nodes to contact the Master to get their configuration enables you to dynamically change the configuration of nodes without having to log in to the remote machine to restart the daemon. You can quickly change the node’s previous data flow configuration to a new one.
The following describes how to "wire" nodes using the Master’s web interface.
On the Master’s web page, click on the config link. You are presented with two forms. These are web interfaces for setting the node’s data flows. When Flume nodes contact the Master, they will notice that the data flow version has changed, instantiate, and activate the configuration.
For this example, you will do the steps you did in the Quick Start section. Enter the following values into the "Configure a node" form, and then click Submit.
| Node name: |
host
|
| Source: |
console
|
| Sink: |
console
|
Refresh the Master page and notice that the version stamp changed to a current time, and that the src and sink fields of the configs updated. After the status changes to "ACTIVE", it is ready to receive console traffic.
On the master, a node can be in one of several states:
On the terminal where your Flume node is running, you should be able to type a few lines and then get output back showing your new log message.
| Node name: |
host
|
| Source: |
text("/etc/services")
|
| Sink: |
console
|
| Note |
|---|---|
You may need to press Enter in the Flume node console. |
Or use these new values to tail a file:
| Node name: |
host
|
| Source: |
tail("/etc/services")
|
| Sink: |
console
|
You can now change the configuration of different nodes in the system to gather data from a variety of sources by going through the Master.
Thus far, you have seen that Flume has a variety of sources that generate or
accept new events that are fed into the system. You have limited the output
of these messages to the console sink. As you would expect, Flume also
provides a wide variety of event sinks — destinations for all of the
events.
There are many possible destinations for events — to local disk, to HDFS, to the console, or forwarding across the network. You use the sink abstractions as an interface for forwarding events to any of these destinations.
You can connect different sources to different sinks by specifying the new
configuration and submitting it to the Master. For example, with the data
flow below, you can make a copy of /etc/services.
| Node name: |
host
|
| Source: |
text("/etc/services")
|
| Sink: |
text("services.copy")
|
![[Warning]](images/warning.png) | Warning |
|---|---|
The |
Notice that the file is copied as is. Sinks have optional arguments for output format, which you can use to write data in other serialization formats. For example, instead of copying a file using the default "raw" formatter, you can format the output using other formatters such as "avrojson" (the Avro serialization json format), "avrodata" (the Avro serialization binary data format), or a "debug" mode (this is the formatter used by the console sink).
If you enter:
| Node name: |
host
|
| Source: |
text("/etc/services")
|
| Sink: |
console("avrojson")
|
You get the file with each record in JSON format displayed to the console.
If you enter:
| Node name: |
host
|
| Source: |
text("/etc/services")
|
| Sink: |
text("services.json", "avrojson")
|
The newly written local services.json file is output in avro’s json format.
There are several sinks you can use. The following list is a subset; see the Appendix for more sinks.
Table 1. Flume Event Sinks
|
|
Null sink. Events are dropped. |
|
|
Console sink. Display to console’s stdout. The "format" argument is optional and defaults to the "debug" output format. |
|
|
Textfile sink. Write the events to text
file |
|
|
DFS seqfile sink. Write serialized Flume events
to a dfs path such as |
|
|
Syslog TCP sink. Forward to events to |
| Warning |
|---|---|
Using |
Using the form for single node configuration of a small number of machines is manageable, but for larger numbers it is more efficient to maintain or auto-generate the configuration for all of the machines in a single file. Flume allows you to set the configurations of many machines in a single aggregated configuration submission.
Instead of the method you used in the "Configuring a Node via the Master" section, put the following configuration line into the "Configure Nodes" form and then submit:
host : text("/etc/services") | console ;Or:
host: text("/etc/services") | text("services.copy");The general format is:
<node1> : <source> | <sink> ; <node2> : <source> | <sink> ; <node3> : <source> | <sink> ; ...
The remainder of this guide uses this format to configure nodes.
A simple network connection is abstractly just another sink. It would be great if sending events over the network was easy, efficient, and reliable. In reality, collecting data from a distributed set of machines and relying on networking connectivity greatly increases the likelihood and kinds of failures that can occur. The bottom line is that providing reliability guarantees introduces complexity and many tradeoffs.
Flume simplifies these problems by providing a predefined topology and tunable
reliability that only requires you to give each Flume node a role. One simple
Flume node topology classifies Flume nodes into two roles — a Flume agent
tier and the Flume collector tier. The agent tier Flume nodes are co-located
on machines with the service that is producing logs. For example, you could
specify a Flume agent configured to have syslogTcp as a source, and
configure the syslog generating server to send its logs to the specified local
port. This Flume agent would have an agentSink as its sink which is
configured to forward data to a node in the collector tier.
Nodes in the collector tier listen for data from multiple agents, aggregates logs, and then eventually write the data to HDFS.
| Warning |
|---|---|
In the next few sections, all |
To demonstrate the new sinks in pseudo-distributed mode, you will instantiate
another Flume node (a physical node) on the local box. To do this, you need
to start a Flume node with some extra options. The command line below starts
a physical node named collector (-n collector):
$ flume node_nowatch -n collector
On the Master’s web page, you should eventually see two nodes: host and
collector. The Flume Node status web pages should be available at http://
localhost:35862 and http://localhost:35863. Port bindings are dependent on
instantiation order — the first physical node instantiated binds on 35862 and
the second binds to 35863.
Next, configure collector to take on the role of a collector, set up
host to send data from the console to the collector by using the
aggregated multiple configuration form. The agent uses the agentSink, a
high reliability network sink. The collector node’s source is configured to
be a collectorSource, and its sink is configured to be the console.
host : console | agentSink("localhost",35853) ;
collector : collectorSource(35853) | console ;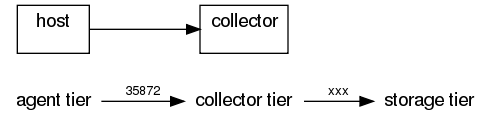
When you type lines in host's console, events are forwarded to the
collector. Currently, there is a bit of latency (15s or so) before the
forwarded message shows up on collector. This is actually a configurable
setting whose default is set to a value that is amenable for high event
throughputs. Later sections describe how to tune Flume.
You have successfully made a event flow from an agent to the collector.
| Tip |
|---|---|
You can check to see if |
A more interesting setup is to have the agent tailing a local file (using the
tail source) or listening for local syslog data (using the syslogTcp or
syslogUdp sources and modifying the syslog daemon’s configuration). Instead
of writing to a console, the collector would write to a collectorSink, a
smarter sink that writes to disk or HDFS, periodically rotates files, and
manages acknowledgements.
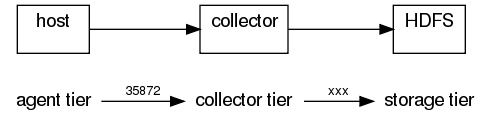
The following configuration is for an agent that listens for syslog messages
and forwards to a collector which writes files to local directory /tmp/flume/
collected/.
host : syslogTcp(5140) | agentSink("localhost",35853) ;
collector : collectorSource(35853) | collectorSink("file:///tmp/flume/collected", "syslog");In the following slightly modified configuration, the collector writes to an
HDFS cluster (assuming the HDFS nameNode is called namenode):
host : syslogTcp(5140) | agentSink("localhost",35853) ;
collector : collectorSource(35853) | collectorSink("hdfs://namenode/user/flume/
","syslog"); | Note |
|---|---|
There are no guarantees that data written to an HDFS file is
durable until the HDFS file is properly closed. Because of this, the
collector sink periodically closes a file and creates a new one in
HDFS. The default time between file rolls (close then open new) is
30s. If you are writing data at low throughput (<2MB/s) you may want
to increase the default time by modifying the
|
This section describes how to start a Master and a node, and configure a node via the Master. The next section describes a more concise way of specifying many configurations, explains agents and collectors, and how to build an agent-collector pipeline on a single machine in a three-tier topology.
The main goal for Flume is to collect logs and data from many different hosts and to scale and intelligently handle different cluster and network topologies.
To deploy Flume on your cluster, do the following steps.
Steps to Deploy Flume On a Cluster
The following section describes how to manually configure the properties file to specify the Master for each node, and how to set default values for parameters. Sections afterwards describe a data flow configuration for a larger system, how to add more capacity by adding collectors, and how to improve the reliability of the Master by adding multiple Masters.
In the previous sections, you used Flume on a single machine with the
default configuration settings. With the default settings, nodes
automatically search for a Master on localhost on a standard
port. In order for the Flume nodes to find the Master in a fully
distributed setup, you must specify site-specific static configuration
settings.
Site-specific settings for Flume nodes and Masters are configured by
properties in the conf/flume-site.xml file found on each machine.
If this file is not present, the commands default to the settings
found in conf/flume-conf.xml. In the following example, you set up
the property that points a Flume node to search for its Master at a
machine called master.
conf/flume-site.xml.
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>flume.master.servers</name> <value>master</value> </property> </configuration>
When you are using agent/collector roles, you can add the following
configuration properties to your flume-site.xml file to set up the
default hosts used as collector.
... <property> <name>flume.collector.event.host</name> <value>collector</value> <description>This is the host name of the default "remote" collector. </description> </property> <property> <name>flume.collector.port</name> <value>35853</value> <description>This default tcp port that the collector listens to in order to receive events it is collecting. </description> </property> ...
This will make the agentSink with no arguments default to using
flume.collector.event.host and flume.collector.port for their
default target and port.
In the following example, a larger setup with several agents push data to a collector. There are seven Flume nodes — six in the agent tier, and one in the collector tier.
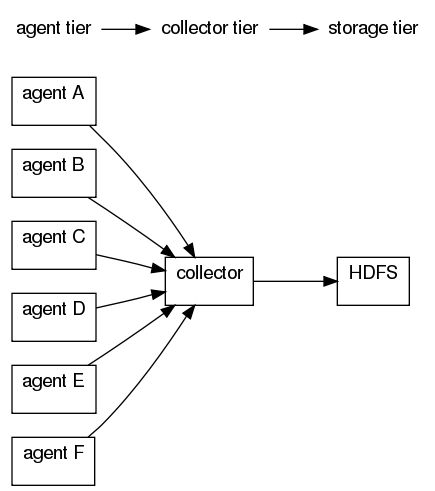
An explicit configuration fills in all of the parameters:
agentA : src | agentSink("collector",35853);
agentB : src | agentSink("collector",35853);
agentC : src | agentSink("collector",35853);
agentD : src | agentSink("collector",35853);
agentE : src | agentSink("collector",35853);
agentF : src | agentSink("collector",35853);
collector : collectorSource(35853) | collectorSink("hdfs://namenode/flume/","srcdata"); | Note |
|---|---|
When specifying destinations for agentSinks, use the hostname and port of the target machine. The default name for a node is its hostname. However, if there are multiple logical nodes, you must use the machine’s host name, not the name of the logical node. In the preceding examples, agent[A-F] and collector are the physical host names of the machines where these configurations are running. |
You can rely on the default ports set in the configuration files:
agentA : src | agentSink("collector");
agentB : src | agentSink("collector");
agentC : src | agentSink("collector");
agentD : src | agentSink("collector");
agentE : src | agentSink("collector");
agentF : src | agentSink("collector");
collector : collectorSource | collectorSink("hdfs://namenode/flume/","srcdata");You can rely on the default ports and default collector host:
agentA : src | agentSink
agentB : src | agentSink
agentC : src | agentSink
agentD : src | agentSink
agentE : src | agentSink
agentF : src | agentSink
collector : collectorSource | collectorSink("hdfs://namenode/flume/","srcdata"); | Warning |
|---|---|
Using defaults can make writing data flow configurations more concise, but may obscure the details about how different nodes are connected to each other. |
Having multiple collectors can increase the log collection throughput and can improve the timeliness of event delivery by increasing collector availability. Data collection is parallelizable; thus, load from many agents can be shared across many several collectors.
The preceding graph and dataflow spec shows a typical topology for Flume nodes. For reliable delivery, in the event that the collector stops operating or disconnects from the agents, the agents would need to store their events to their respective disks locally. The agents would then periodically attempt to recontact a collector. Because the collector is down, any analysis or processing downstream is blocked.
When you have multiple collectors as in the preceding graph and dataflow spec, downstream progress is still made even in the face of a collector’s failure. If collector B goes down, agent A, agent B, agent E, and agent F continue to deliver events via collector A and collector C respectively. Agent C and agent D may have to queue their logs until collector B (or its replacement) comes back online.
The following configuration partitions the work from the set of agents across many collectors. In this example, each of the collectors specify the same DFS output directory and file prefixes, aggregating all of the logs into the same directory.
agentA : src | agentE2ESink("collectorA",35853);
agentB : src | agentE2ESink("collectorA",35853);
agentC : src | agentE2ESink("collectorB",35853);
agentD : src | agentE2ESink("collectorB",35853);
agentE : src | agentE2ESink("collectorC",35853);
agentF : src | agentE2ESink("collectorC",35853);
collectorA : collectorSource(35853) | collectorSink("hdfs://...","src");
collectorB : collectorSource(35853) | collectorSink("hdfs://...","src");
collectorC : collectorSource(35853) | collectorSink("hdfs://...","src");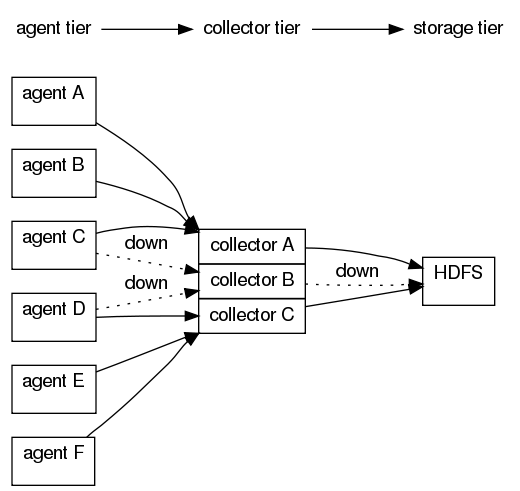
When you have multiple collectors writing to the same storage location, instead of having agent C and agent D queue indefinitely, you can instead have them fail over to other collectors. In this scenario, you could have agent C and agent D fail over to collector A and collector C respectively, while periodically checking to see if collector B has returned.
To specify these setups, use agents with failover chains. Similarly
to single collector agents, there are three levels of reliability for
the failover chain agents: agentE2EChain, agentDFOChain, and
agentBEChain.
In the following example, you manually specify the failover chain
using agentE2EChain, an agent with end-to-end reliability with
multiple failover collectors. agentA in this situation will
initially attempt to send to collectorA on port 35853. The second
argument in agentA 's sink specifies the collector to fall back onto
if the first fails. You can specify an arbitrary number of
collectors, but you must specify at least one.
agentA : src | agentE2EChain("collectorA:35853","collectorB:35853");
agentB : src | agentE2EChain("collectorA:35853","collectorC:35853");
agentC : src | agentE2EChain("collectorB:35853","collectorA:35853");
agentD : src | agentE2EChain("collectorB:35853","collectorC:35853");
agentE : src | agentE2EChain("collectorC:35853","collectorA:35853");
agentF : src | agentE2EChain("collectorC:35853","collectorB:35853");
collectorA : collectorSource(35853) | collectorSink("hdfs://...","src");
collectorB : collectorSource(35853) | collectorSink("hdfs://...","src");
collectorC : collectorSource(35853) | collectorSink("hdfs://...","src"); | Note |
|---|---|
In this section, |
As in the single collector case, if no port number is specified, the agent defaults to using the flume.collector.port.
agentA : src | agentE2EChain("collectorA","collectorB");
agentB : src | agentE2EChain("collectorA","collectorC");
agentC : src | agentE2EChain("collectorB","collectorA");
agentD : src | agentE2EChain("collectorB","collectorC");
agentE : src | agentE2EChain("collectorC","collectorA");
agentF : src | agentE2EChain("collectorC","collectorB"); collectorA : collectorSource | collectorSink("hdfs://...","src");
collectorB : collectorSource | collectorSink("hdfs://...","src");
collectorC : collectorSource | collectorSink("hdfs://...","src"); | Warning |
|---|---|
The automatic failover chain feature does not currently work when using multiple masters. |
Flume also provides a mechanism that automatically assigns failover chains based on how nodes are configured. As collector nodes are assigned in the Flume Master, the Master attempts to distribute the agents evenly amongst the collectors. In the face of failure, each agent is assigned a different failover chain. This mitigates the chances of another collector becoming overloaded in the event of failure of a collector.
To specify a node to use the failover chains, use either the autoE2EChain, autoDFOChain, or autoBEChain agent sink. Because the Master calculates the failover chains, these sinks take no explicit arguments.
agentA : src | autoE2EChain ;
agentB : src | autoE2EChain ;
agentC : src | autoE2EChain ;
agentD : src | autoE2EChain ;
agentE : src | autoE2EChain ;
agentF : src | autoE2EChain ;
collectorA : autoCollectorSource | collectorSink("hdfs://...", "src");
collectorB : autoCollectorSource | collectorSink("hdfs://...", "src");
collectorC : autoCollectorSource | collectorSink("hdfs://...", "src");The Master updates the configuration of the agents based on the current collectors in the system. When new collectors are added to the system, the Master updates the failover chains of agents to rebalance.
| Note |
|---|---|
If the Master has no nodes with |
| Tip |
|---|---|
You can see the translation of the auto*Chain configuration in the node configuration table under the translated configuration column. This is a little declarative specification of the failure recovery behavior of the sink. More details on this are in the Advanced section of this guide, and in future revisions the translations for the agents and other chains will also be presented. |
Manually configuring nodes in Flume is manageable for a small number of nodes, but can become burdensome for an operator as demands inevitably grow. Ideally, the operator only has to assign a role to a particular machine. Because configuration management is centralized via the Master, the Master potentially has all the information necessary to intelligently create a node topology and isolate flows of data from each other.
To explain how this can be done, the concept of a logical node is introduced. To manage communications between logical nodes, the concepts of logical sources and logical sinks are introduced. To isolate different groups of nodes, the concept of a flow is introduced that allows you to group agents and collectors into separate and isolated groups.
The logical node abstraction allows for each JVM instance (a physical node) to contain multiple logical nodes. This allows for the processing of many source sink combinations on many threads of execution to occur on a single JVM instance.
Each logical node has a name that may be completely different from its physical name or hostname. You now need new operations that enable you to spawn a new node, map logical nodes to physical nodes, and decommission existing logical nodes.
| Note |
|---|---|
The following commands are entered via the web interface using the "raw command" web page on the Master. You might prefer using the Flume command shell (described in a later section) for these operations. The same commands described in this section can be entered in web interface or entered at the command shell by prefixing the command with exec. |
Suppose that initially you know you want an agent-collector topology, but you don’t know the particular names of the exact machines. For now, you can specify the configuration of the logical nodes without specifying any physical machine names.
agent1 : _source_ | autoBEChain ;
collector1 : autoCollectorSource | collectorSink("hdfs://....") ;Later you learn that host1 is the name of the agent1 machine and host2 is the name of the collector machine. You can map logical nodes onto the physical Flume instances on host1 and host2 by issuing the following map commands:
map host1 agent1 map host2 collector1
Afterwards, the node status table should display a new row of information for each logical node. Each logical node reports its own execution state, configuration, and heartbeat. There is also a new entry in the logical node mapping table showing that the logical node has been placed on the specified physical node. To configure the node’s sources and sinks, use exactly the same mechanisms described in the previous sections.
You can also remove a logical node by using the decommission command. Suppose you no longer needed agent1 and wanted to "turn it off". You can do so by entering the following command:
decommission agent1
This terminates the thread and removes the configuration associated with a logical node, and the mapping between the logical node and physical node.
You can also move a logical node from one physical node to another by first unmapping a logical node and then mapping it on another physical node. In this scenario, you change the collector1 from being on host2 to host3.
unmap host2 collector1
At this point, the logical node mapping is removed, and collector1 is not active anywhere. You can then map collector1 onto host3 by using the map command:
map host3 collector1
| Note |
|---|---|
Logical nodes are not templates — if you want to have the same source/sink pairs on a particular physical node, you need to have a logical node for each. When adminstering many logical nodes it is often useful to write a script that generates configurations and unique individual logical node names. Using the part of a host name is a common pattern. |
| Warning |
|---|---|
The logical sources and logical sinks feature does not currently work when using multiple masters. |
In the previous example, we used two abstractions under-the-covers that allow the specifications of a graph topology for communications without having to use physical hostnames and ports. These abstractions — the logical source and logical sink — allow you to create a different graph topology without having to know physical machines until they are mapped.
Suppose you have two nodes producing data and sending it to the consumer:
dataProducer1 : console | logicalSink("dataConsumer") ;
dataProducer2 : console | logicalSink("dataConsumer") ;
dataConsumer : logicalSource | console ;Note that in this example, the destination argument is the logical name of the node and not a specific host/port combination.
To implement these features, there is a generalized mechanism where users enter logical configurations that are translated by the Master to a physical configuration.
When the logical nodes get mapped to physical nodes:
map host1 dataProducer1 map host2 dataProducer2 map host3 dataConsumer
and after the Master learns the host names (the host1, host2, and host3 machine’s heartbeat against the Master), the Master has enough information to translate configurations with physical hostnames and ports. A possible translation would replace the logicalSource with a rpcSources and the logicalSink with an rpcSinks:
dataProducer1 : console | rpcSink("host3",56789) ;
dataProducer2 : console | rpcSink("host3",56789) ;
dataConsumer : rpcSource(56789) | console ;In fact, auto agents and collectors, are another example of translated sources and sinks. These translate auto*Chain sinks and collectorSource into a configuration that uses logicalSinks and logicalSources which in turn are translated into physical rpcSource and rpcSinks instances.
| Tip |
|---|---|
Translations are powerful and can be fairly smart; if new collectors are added, they will become new failover options. If collectors are removed, then the removed collectors will be automatically replaced by other failover nodes. |
| Warning |
|---|---|
The automatic flow isolation feature does not currently work when using multiple masters. |
What happens if you want collect different kinds of data from the same physical node? For example, suppose you wanted to collect httpd logs as well as syslog logs from the same physical machine. Suppose also you want to write all of the syslog data from the cluster in one directory tree, and all of the httpd logs from the cluster in another.
One approach is to tag all the data with source information and then push all the data down the same pipe. This could then be followed by some post- processing that demultiplexes (demuxes) the data into different buckets. Another approach is to keep the two sets of data logically isolated from each other the entire time and avoid post processing.
Flume can do both approaches but enables the latter lower-latency approach, by introducing the concept of grouping nodes into flows. Since there are logical nodes that allow for multiple nodes on a single JVM, you can have a node for each different kinds of produced data.
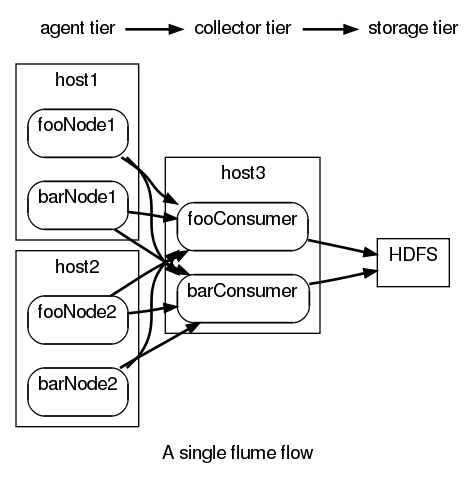
The following example shows how flows can be used. Start by having six logical nodes in the system.
fooNode1 : fooSrc | autoBEChain ;
barNode1 : barSrc | autoBEChain ;
forNode2 : fooSrc | autoBEChain ;
barNode2 : barSrc | autoBEChain ;
fooConsumer : autoCollectorSource | collectorSink("hdfs://nn/foodir") ;
barConsumer : autoCollectorSource | collectorSink("hdfs://nn/bardir") ;In this scenario, there are two physical machines that produce both kinds of data — foo data and bar data. You want to send data to single collector that collects both foo data and bar data and writes it to different HDFS directories. You could then map the nodes onto physical nodes:
map host1 fooNode1 map host1 barNode1 map host2 fooNode2 map host2 barNode2 map host3 fooConsumer map host3 barConsumer
This setup essentially instantiates the first approach. It mixes foo and bar data together since the translation of autoBEChain would see two collectorSources that the Master considers to be equivalent. Foo data will likely be sent to the barConsumer and bar data will likely be sent to fooConsumer.
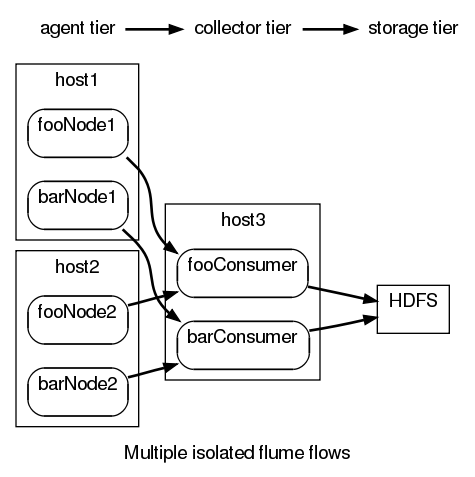
You really wanted to separate sources of information into logically isolated streams of data. Flume provides a grouping abstraction called a flow. A flow groups particular logical nodes together so that the different logical data types remain isolated.
More concretely, it allows for a different failover chain for each kind of data in the Flume cluster. The auto*Chain based agents would only send data to collectors in the same flow group. This isolates data so that it only flows to nodes within the group.
Currently, the compact form of the configuration language does not allow you to specify flows. Instead you must add an extra argument to the config command to specify a flow.
This example shows commands that would be entered in the Flume shell without flow group information. In this case all of the nodes are in the same flow.
exec config fooNode1 fooSrc autoBEChain
exec config barNode1 barSrc autoBEChain
exec config fooNode2 fooSrc autoBEChain
exec config barNode2 barSrc autoBEChain
exec config fooConsumer autoCollectorSource 'collectorSink("hdfs://nn/foodir")'
exec config barConsumer autoCollectorSource 'collectorSink("hdfs://nn/bardir")'Now using the following commands you can specify flows by adding an extra parameter after the node name. In this example we have two flows: flowfoo and flowbar. flowfoo contains fooNode1, fooNode2 and fooConsumer. flowbar contains barNode1, barNode2 and barConsumer.
exec config fooNode1 flowfoo fooSrc autoBEChain
exec config barNode1 flowbar barSrc autoBEChain
exec config fooNode2 flowfoo fooSrc autoBEChain
exec config barNode2 flowbar barSrc autoBEChain
exec config fooConsumer flowfoo autoCollectorSource 'collectorSink("hdfs://nn/foodir")'
exec config barConsumer flowbar autoCollectorSource 'collectorSink("hdfs://nn/bardir")'By using these commands, the data from fooNode1 and fooNode2 will only be sent to fooConsumer, and barNode1 and barNode2’s data will only be sent to barConsumer. Data from one node is not mixed with other data from other nodes unless explicitly connected.
| Tip |
|---|---|
In practice it is a good idea to use different node names and different flow ids for different kinds of data. When node names are reused, the default behavior is to attempt to recover from failures assuming that leftover data from a crashed execution or previous source/sink configuration version are still producing the same kind of data. |
This section introduced logical nodes, logical sources, logical sinks, and flows and showed how these abstractions enable you to automatically deal with manageability problems.
The translation mechanism can be quite powerful. When coupled with metrics information, this could be used to perform automated dynamic configuration changes. A possible example would be to automatically commission or decommission new collectors to match diurnal traffic and load patterns.
| Warning |
|---|---|
The automatic failover chains, automatic flow isolation, and logical source/sink feature does not currently work when using multiple masters. |
The Master has two main jobs to perform. The first is to keep track of all the nodes in a Flume deployment and to keep them informed of any changes to their configuration. The second is to track acknowledgements from the end of a Flume flow that is operating in reliable mode so that the source at the top of that flow knows when to stop transmitting an event.
Both these jobs are critical to the operation of a Flume deployment. Therefore, it is ill-advised to have the Master live on a single machine, as this represents a single point of failure for the whole Flume service (see failure modes for more detail).
Flume therefore supports the notion of multiple Masters which run on physically separate nodes and co-ordinate amongst themselves to stay synchronized. If a single Master should fail, the other Masters can take over its duties and keep all live flows functioning. This all happens transparently with a little effort at configuration time. Nodes will automatically fail over to a working Master when they lose contact with their current Master.
The Flume Master can be run in one of two ways.
Large production deployments of Flume should run a distributed Master so that inevitable machine failures do not impact the availability of Flume itself. For small deployments the issue is less clear-cut - a distributed Master means reserving more computing resources that could be used instead for nodes or other services, and it is possible to recover from many failure modes in a timely manner with human intervention. The choice between distributed and standalone Masters is ultimately dependent both on your use case and your operating requirements.
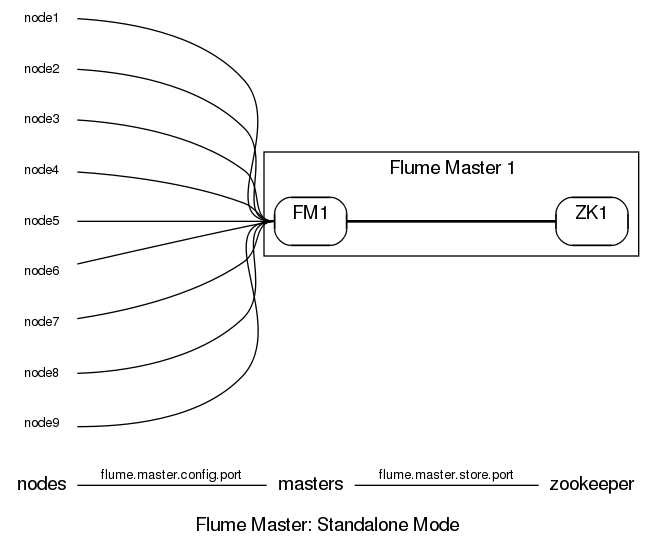
Whether the Flume Master starts in distributed or standalone mode is indirectly controlled by how many machines are configured to run as Master servers. To run in standalone mode, a single configuration property flume.master.servers must be set:
<property> <name>flume.master.servers</name> <value>hostA</value> </property>
The value of flume.master.servers is a comma-separated list of all the machine names (or IP addresses) that will be Master servers. If this list contains only machine name, the Flume Master will start in standalone mode. If there is more than one machine name in the list, the Flume Master will start in distributed mode.
There’s no other configuration required for standalone mode. Flume will use reasonable default values for any other master-related variables. To start the Master, from the command prompt type:
$ flume master
from $FLUME_HOME. A number of log messages should print to the screen. After the server is running, you can check that everything is working properly by visiting the web interface at http://master-node-ip:35871/,
where master-node-ip is the IP address (or hostname) of the Master node. If you see a web page, the Master is running.
How many machines do I need? The distributed Flume Master will continue to work correctly as long as more than half the physical machines running it are still working and haven’t crashed. Therefore if you want to survive one fault, you need three machines (because 3-1 = 2 > 3/2). For every extra fault you want to tolerate, add another two machines, so for two faults you need five machines. Note that having an even number of machines doesn’t make the Flume Master any more fault-tolerant - four machines only tolerate one failure, because if two were to fail only two would be left functioning, which is not more than half of four. Common deployments should be well served by three or five machines.
Note. flume.master.serverid is the only Flume Master property that must be different on every machine in the ensemble. *
masterA.
<property> <name>flume.master.serverid</name> <value>0</value> </property>
masterB.
<property> <name>flume.master.serverid</name> <value>1</value> </property>
masterC.
<property> <name>flume.master.serverid</name> <value>2</value> </property>
The value for flume.master.serverid for each node is the index of
that node’s hostname in the list in flume.master.ensemble, starting
at 0. For example masterB has index 1 in that list. The purpose of
this property is to allow each node to uniquely identify itself to the
other nodes in the Flume Master.
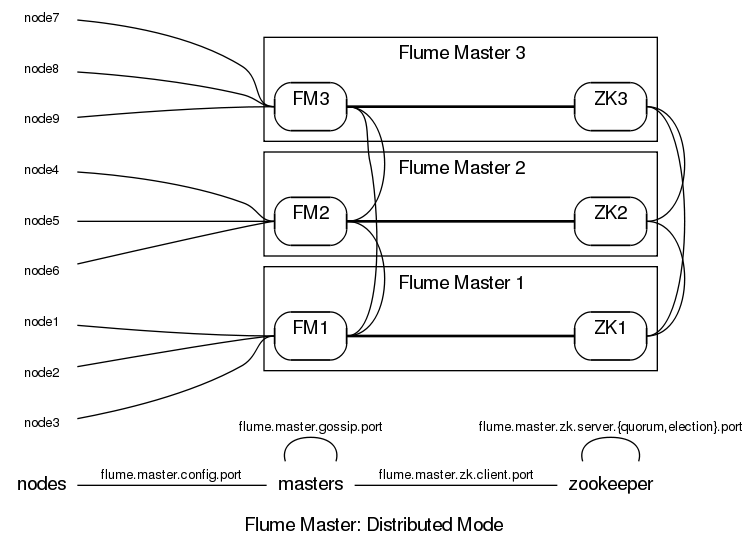
This is all the configuration required to start a three-node distributed Flume Master. To test this out, we can start the Master process on all three machines:
[flume@masterA] flume master [flume@masterB] flume master [flume@masterC] flume master
Each Master process will initially try and contact all other nodes in the ensemble. Until more than half (in this case, two) nodes are alive and contactable, the configuration store will be unable to start, and the Flume Master will not be able to read or write configuration data.
You can check the current state of the ensemble by inspecting the web page for any of the Flume Master machines which by default will be found at, for example, http://masterA:35871.
The Flume Master stores all its data in a configuration store. Flume has a pluggable configuration store architecture, and supports two implementations.
Flume and Apache ZooKeeper . Flume relies on the Apache ZooKeeper coordination platform to provide reliable, consistent, and persistent storage for node configuration data. A ZooKeeper ensemble is made up of two or more nodes which communicate regularly with each other to make sure each is up to date. Flume embeds a ZooKeeper server inside the Master process, so starting and maintaining the service is taken care of. However, if you have an existing ZooKeeper service running, Flume supports using that external cluster as well.
In almost all cases, you should use the ZBCS. It is more reliable and fault-tolerant, and will recover configurations after a restart. It is compatible with both standalone and distributed deployments of the Flume Master.
The MBCS is appropriate if you are experimenting with Flume and can stand to lose configuration if the machine fails.
ZBCS is the default configuration store. The choice of which configuration store to use is controlled by the flume.master.store system property.
<property> <name>flume.master.store</name> <value>zookeeper</value> </property>
If set to memory, the Flume Master will use MBCS instead. This is only supported in standalone mode.
Most deployments using the ZBCS can use Flume’s default configuration. However, where more control over the precise configuration of the Flume Master is needed, there are several properties that you can set.
flume.master.zk.logdir
flume.master.zk.logdir. This directory must be writable by the user as which Flume is running, and will be created if it doesn’t exist at start-up time. WARNING: Do not delete this directory, or any files inside it. If deleted, all your configuration information will be lost.
flume.master.zk.server.quorum.port and flume.master.zk.server.election.port. The defaults are 3182 and 3183 respectively. Note that these settings control both the port on which the ZBCS listens, and on which it looks for other machines in the ensemble.
flume.master.zk.client.port
flume.master.zk.client.port. The default is 3181.
Flume Master servers also use a gossip protocol to exchange information between themselves. Each server periodically wakes and picks another machine to send new data to. This protocol by default uses TCP port 57890, but this is controlled via the flume.master.gossipport property:
<property> <name>flume.master.gossip.port</name> <value>57890</value> </property>
In standalone mode, there is no need to use gossip, so this port is unused.
One property needs to be set to configure a Flume Node to connect to multiple Masters: flume.master.servers.
<property> <name>flume.master.servers</name> <value>masterA,masterB,masterC</value> </property>
The nodes connect over the port flume.master.heartbeat.port on each machine in the Flume Master - this is the port that the Master servers listen on for node heartbeats.
If a Master server fails, nodes will automatically fail over to the next randomly selected Master server that they can establish a connection to.
In some cases you may want a ZBCS that relies on an externally managed ZooKeeper service. The most common example of this is where multiple services which rely on ZooKeeper are being used (Flume and Hbase for example). In the following example zkServer{A,B,C}:2181 should be replaced with the hostname/port of the ZooKeeper servers which make up your ensemble.
conf/flume-site.xml.
<property> <name>flume.master.zk.use.external</name> <value>true</value> </property> <property> <name>flume.master.zk.servers</name> <value>zkServerA:2181,zkServerB:2181,zkServerC:2181</value> </property>
This section described installing, deploying, and configuring a set of Flume nodes in a fully distributed setting. You should now be able to collect streams of logs with Flume.
You also used some roles for sources and sinks to connect nodes together. You now have an understanding of the basics of setting up a set of Flume nodes. Here’s the new sources and sinks introduced in this subsection.
Flume’s Tiered Event Sources
collectorSource[(port)]
port. If port is not specified, the
node default collector TCP port, 35853.
Flume’s source interface is designed to be simple yet powerful and enable logging of all kinds of data — from unstructured blobs of byte, semi-structured blobs with structured metadata, to completely structured data.
In this section we describe some of the basic mechanisms that can be used to pull in data. Generally, this approach has three flavors. Pushing data to Flume, having Flume polling for data, or embedding Flume or Flume components into an application.
These mechanisms have different trade-offs — based on the semantics of the operation.
Also, some sources can be one shot or continuous sources.
syslogTcp, syslogUdp
scribe
tail, multitail
exec
poller
| Warning |
|---|---|
these features are incomplete. |
log4j
simple client library
// move this to gathering data from sources
Flume includes specific integration support for Apache Log4j that allows end
user applications to log directly to a Flume agent with no code modification.
This support comes in the form of a log4j appender and can be configured in an
application’s log4j.properties or log4j.xml file as you would with any of
the built-in appenders. The appender uses Flume’s avroSource() and converts
each log4j LoggingEvent into a Flume Avro event that can be natively handled
by Flume.
To configure log4j to log to Flume:
com.cloudera.flume.log4j.appender.FlumeLog4jAvroAppender
appender in the log4j configuration file.
To use the Flume Avro appender, you must have the following jars on your application’s classpath:
flume-log4j-appender-version.jar
flume-core-version.jar
Avro jar files and its dependencies are also required.
The simplest way to ensure all dependencies are properly included in your application’s classpath is to use a build system such as Maven that handles transitive dependencies for you. Flume’s log4j appender is available as a Maven project and will properly include Avro dependencies.
The Flume Avro appender has a number of options users can set to affect its
behavior. The only parameter that absolutely must be set is the port on which
the Flume avroSource is listening. The appender assumes the Flume agent is
running locally and that we can communicate via the hostname localhost. Users
can also control the number of times to attempt reconnection before a logging
call fails.
Parameters
hostname
localhost)
port
reconnectAttempts
avroSource() before throwing an exception. A setting of 0 (zero) means to
try forever. (default: 10)
Example log4j.properties.
log4j.debug = true log4j.rootLogger = INFO, flume log4j.appender.flume = com.cloudera.flume.log4j.appender.FlumeLog4jAvroAppender log4j.appender.flume.layout = org.apache.log4j.TTCCLayout log4j.appender.flume.port = 12345 log4j.appender.flume.hostname = localhost log4j.appender.flume.reconnectAttempts = 10
Example Flume configuration.
my-app : avroSource(12345) | agentE2ESink("my-app-col", 12346)
my-app-col : collectorSource(12346) | collectorSink("hdfs://...", "my-app-")
Note how the port referenced in the log4j.properties example matches that of
the avroSource() in the Flume configuration example.
Notes. The FlumeLog4jAvroAppender uses no buffering internally. This is because
buffering would potentially create a case where, even if a Flume node is
configured as end-to-end durable, events in the appender’s internal buffer
could be lost in the event of a failure.
By setting the reconnectAttempts parameter to zero (i.e. retry forever) you
can ensure the end user application blocks should the Flume agent become
unavailable. This is meant to satisfy users who have a zero data loss
requirement where it’s better to stop service than to not be able to log that
it occurred.
The first goal of Flume is to collect data and reliably write it to HDFS. Once data arrives, one wants the ability to control where and in what format data is stored. Flume provides basic output control mechanisms via the properties configuration and in the dataflow language. This gives the user the ability to control the output format and output bucketing of incoming data, and simplifies integration with other HDFS data consumers such as Hive and HBase.
Here are some example use cases:
To support these kinds of features, Flume uses a simple data model, provides a mechanism for bucketing events, and also provides basic extraction operations for specifying custom bucketing discriminators.
A Flume event has these six main fields:
All events are guaranteed to have all of these elements. However, the body may have zero length, and the metadata table can be empty.
The Unix timestamp is measured in milliseconds and is Unix time stamp from the source machine. The nanosecond timestamp is machine specific nanosecond counter also from the source machine. It is safe to assume that the nanotime from a machine is monotonically increasing — i.e. if event A has a larger nanotime than event B from the same machine, event A was initially received before event B.
Currently the priority of a message can have one of 6 values: TRACE, DEBUG, INFO, WARN, ERROR, or FATAL. These values are often provided by logging systems such as syslog or log4j.
The source host is the name of the machine or the IP (whatever hostname call returns).
The body is the raw log entry body. The default is to truncate the body to a maximum of 32KB per event. This is a configurable value and can be changed by modifying the flume.event.max.size.bytes property.
Finally there is the metadata table which is a map from a string attribute name to an arbitrary array of bytes. This allows for custom bucketing attributes and will be described in more depth in the Advanced Usage section of this guide.
You can control the output of events to particular directories or files based on the values of an event’s fields. To enable this, you provide an escaping mechanism that outputs data to a particular path.
For example, here is an output spec:
collectorSink("hdfs://namenode/flume/webdata/%H00/", "%{host}-")The first argument is the directory where data is to be written. The second is a filename prefix where events are written. Suppose you get an event from a machine called server1 generated at time 18:58. The events would get written to HDFS with namenode namenode, in a directory called /flume/webdata/1800/, with files named server1-xxx where xxx is some extra data for unique file names.
What happened here? Flume replaced the %H with a string that represent the hour of the timestamp found in the event’s data. Likewise, the %o was replace with the hostname field from the event.
What happens if the server1’s message had been delayed and the message wasn’t sent downstream until 19:05? Since the value of the timestamp on the event was during the 18:00 hour, the event would be written into that directory.
Event data escape sequences
Because bucketing by date is a frequently-requested feature, there are escape sequences for finer control of date values that allow you to bucket data based on date.
Here is another output spec:
collectorSink("hdfs://namenode/flume/webdata/%Y-%m-%d/%H00/", "web-")This would create directories for each day, each with a subdirectory for each hour with filenames prefixed "web-".
Table 2. Fine grained escape sequences date and times
|
%a |
locale’s short weekday name (Mon, Tue, …) |
|
%A |
locale’s full weekday name (Monday, Tuesday, …) |
|
%b |
locale’s short month name (Jan, Feb,…) |
|
%B |
locale’s long month name (January, February,…) |
|
%c |
locale’s date and time (Thu Mar 3 23:05:25 2005) |
|
%d |
day of month (01) |
|
%D |
date; same as %m/%d/%y |
|
%H |
hour (00..23) |
|
%I |
hour (01..12) |
|
%j |
day of year (001..366) |
|
%k |
hour ( 0..23) |
|
%l |
hour ( 1..12) |
|
%m |
month (01..12) |
|
%M |
minute (00..59) |
|
%P |
locale’s equivalent of am or pm |
|
%s |
seconds since 1970-01-01 00:00:00 UTC |
|
%S |
second (00..60) |
|
%y |
last two digits of year (00..99) |
|
%Y |
year (2010) |
|
%z |
+hhmm numeric timezone (for example, -0400) |
Now that you have control of where files go, this section describes how you can control the output format of data. There are two ways to this. The first is to set the default value in flume-site.xml and the other is by specifying output format in particular sinks.
You can set the default output format by etting the
flume.collector.output.format property set in the flume-site.xml
file. The output formats are:
Table 3. Output formats
|
avro |
Avro Native file format. Default currently is uncompressed. |
|
avrodata |
Binary encoded data written in the avro binary format. |
|
avrojson |
JSON encoded data generated by avro. |
|
default |
a debugging format. |
|
json |
JSON encoded data. |
|
log4j |
a log4j pattern similar to that used by CDH output pattern. |
|
raw |
Event body only. This is most similar to copying a file but does not preserve any uniqifying metadata like host/timestamp/nanos. |
|
syslog |
a syslog like text output format. |
|
seqfile |
the binary hadoop Sequence file format with WritableEventKeys keys, and WritableEvent as values. |
Here is an example of a property added to the flume-site.xml file:
<property>
<name>flume.collector.output.format</name>
<value>avrojson</value>
<description>This is the output format for the data written to the
collector. There are several formats available:
avro - Avro Native file format. Default currently is uncompressed.
avrodata - this outputs data as an avro binary encoded data
avrojson - this outputs data as json encoded by avro
debug - this is a format for debugging
json - this outputs data as json
log4j - outputs events in a pattern similar to Hadoop's log4j pattern
raw - Event body only. This is most similar to copying a file but
does not preserve any uniqifying metadata like host/timestamp/nanos.
seqfile - this is the hadoop sequence file format with
WritableEventKeys and WritableEvent objects.
syslog - outputs events in a syslog-like format
</description>
</property>Some sinks have an optional output format argument. These include the
console, text, customdfs/formatDfs,
escapedCustomDfs/escapedFormatDfs, and collectorSink.
In these cases, we will be focusing on the optional format argument.
collectorSink( "dfsdir","prefix"[, rollmillis[, format]])
text("file"[,format])
formatDfs("hdfs://nn/file" [, format])
escapedFormatDfs("hdfs://nn/file" [, format])This mechanism is more flexible because it allows for output formats
with arguments. Currently, the seqfile output format supports
arugments for specifying an sequence file internal compression codec.
Codecs available for use are the same as those available to hadoop — generally these include gzip, bzip2, and can include others that
have been plugged in such lzo or snappy.
The compression codec is specified by adding an argument to output
format. For example, the seqfile output format accepts a
compression codec argument. So, to specify an output format that is a
sequence file using the bzip2 codec, the output format would be
seqfile("bzip2"). To write bzip2 compressed sequence files, using a
formatDfs sink, we would specify formatDfs("hdfs://nn/dir/file",
seqfile("bzip2"))
| Note |
|---|---|
The old syntax requires specifying a Flume String (ex:
|
For all versions Hadoop’s file system that are earlier than 0.20.x, HDFS has write-once read-many semantics. Thus, the only way to reliably flush an HDFS file is to close the file. Moreover, once a file is closed, no new data can be appended to the file. This presents a tension between getting data written quickly to HDFS and potentially having many small files (which is a potential scalability bottleneck of HDFS).
On one side, to minimize the load and data stored throughput the system, ideally one would flush data to HDFS as soon as it arrives. Flushing frequently is in conflict with efficiently storing data to HDFS because this could result in many small files, which eventually will stress an HDFS namenode. A compromise is to pick a reasonable trigger that has a collector close "reasonably-sized" files (ideally larger than a single HDFS block, 64MB by default).
When Flume is deployed at a scale where data collection volumes are small, it may take a long time to reach the ideal minimum file size (a block size, typically 64MB). For example, if a single web server produces 10k of logs a second (approx. 100 hit logs/s at 100B per log), it will take about 2 hours (6400 seconds) before an ideal file size can reached.
In these situations, lean towards having more small files. Small files cause a few problems downstream. These include potential scaling limitations of Hadoop’s HDFS, and performance penalties when using MapReduce’s default input processing mechanisms within Hadoop.
The following sections describe two mechanisms to mitigate these potential problems:
This particular problem becomes less of an issue when the scale of logging goes up. If a hundred machines were generating the same amount of logs, you would reach reasonable files sizes every 64 seconds.
Future versions of Hadoop will mitigate this problem by providing a flush/sync operation for currently open HDFS files (patch is already slated for Hadoop HDFS 0.21.x).
Flume supports basic compression for all log files that are written to HDFS. Compressed files are automatically suffixed with an extension and follow the same naming format + directory structure as regular log files.
If GzipCodec is selected, ".gz" is appended to the file name, if BZip2Codec is selected, ".bz2" is appended.
| Note |
|---|---|
SequenceFiles ( |
<property>
<name>flume.collector.dfs.compress.codec</name>
<value>None</value>
<description>Writes formatted data compressed in specified codec to
dfs. Value is None, GzipCodec, DefaultCodec (deflate), BZip2Codec,
or any other Codec Hadoop is aware of </description>
</property>This section describes in further detail, how to automate the control of Flume nodes via the FlumeShell, a deep dive into Flume’s dataflow specification language, internals of the reliability mechanisms, how to do metadata manipulations, and how to install source and sink plugins.
So far, you have been modifying the state of Flume using a simple (but primitive) web interface to a Master server.
Flume also provides a shell, which allows the user to type commands into a terminal and have them executed on a Flume deployment.
All of the commands available in the web form are available in the Flume Shell. The Flume Shell, however, actually has extra controls for command submission control and state checking that aid scriptability.
You can start the FlumeShell by running flume shell in a terminal window.
The connect command can be used to establish a connection to any Master
server.
hostname:~/flume$ flume shell [flume (disconnected)] connect localhost:35873 Connecting to Flume master localhost:35873... [flume localhost:35873]
hostname:~/flume$ flume shell -c localhost:35873 Connecting to Flume master localhost:35873... [flume localhost:35873]
The command line parameters for the Flume Shell are as follows:
usage: FlumeShell [-c <arg>] [-e <arg>] [-q] [-s <arg>] -? Command line usage help -c <arg> Connect to master:port -e <arg> Run a single command -q Run in quiet mode - only print command results -s <arg> Run a FlumeShell script
The FlumeShell makes scripting Flume possible - either by using a single
invocation with -e or by running a script of commands with -s. It is also
possible to pipe stdin to the FlumeShell as in the following example:
echo "connect localhost:35873\ngetconfigs\nquit" | flume shell -q
Flume Commands. You can press Tab any time for some hints on available commands. If you start typing a command you can use TAB to complete command.
help
connect master:port
config logicalnode source sink
getnodestatus
getconfigs
getmappings [physical node]
exec
source file
submit
wait ms [cmdid]
ms milliseconds
until cmdid has entered the SUCCEEDED or FAILED state. If ms is 0 the
command may block forever. If the command times out, the shell will
disconnect. This is useful in conjunction with submitted commands.
waitForNodesActive ms node1 [node2 […]]
ms milliseconds until the specified list of nodes have entered the ACTIVE or
CONFIGURING state. If ms==0 then the command may block forever.
waitForNodesDone ms node1 [node2 […]]
ms milliseconds until the specified list of nodes have entered the IDLE,
ERROR, or LOST state.
quit
Exec and Submit commands. Both the web form and the FlumeShell are interfaces to the same command processing infrastructure inside Flume. This section introduces the FlumeShell and show how you can use it to make administering Flume more simple.
These commands are issued and run as if run from the master. In the command shell they have the form:
exec command [arg1 [_arg2 [ … ] ] ]
submit command [arg1 [_arg2 [ … ] ] ]
Complex arguments like those with spaces, or non alpha-numeric characters can be expressed by using "double quotes"s and `single quotes’s. If enclosed in double quotes, the bodies of the strings are Java string unescaped. If they are enclosed in single quotes, arbitrary characters can be included except for the ' character.
exec commands block until they are completed. submit commands are
asynchronously sent to the master in order to be executed. wait are
essentially joins for recently submit ted commands.
noop
config logicalnode source sink
multiconfig flumespec
unconfig logicalnode
null source and a null state. +refresh
refreshAll logicalnode
save filename
load filename
filename.
map physicalnode logicalnode
physicalnode. The node starts with a
null source and a null sink, and updates its configuration specified at the
master when it begins heartbeating. Thus if a logical node configuration
already exists and is mapped, it will pick up the configuration for the logical
node.
spawn physicalnode logicalnode
spawn: command is a synonym for the
+map command and has been deprecated.
decommission logicalnode
unmap physicalnode logicalnode
map command.
unmapAll
map command.
purge logicalnode
purgeAll
Using the Flume node roles (collector, agent) is the simplest method to get up and running with Flume. Under the covers, these sources and sinks (collectorSink, collectorSource, and agentSource) are actually composed of primitive sinks that have been augmented with translated components with role defaults, special sinks and sink decorators. These components make configuration more flexible, but also make configuration more complicated. The combination of special sinks and decorators expose a lot of details of the underlying mechanisms but are a powerful and expressive way to encode rich behavior.
Flume enables users to enter their own composition of sinks, sources, and decorators by using a domain specific data flow language. The following sections will describe this in more details.
nodeName ::= NodeId
simpleSource ::= SourceId args?
simpleSink ::= SinkId args?
decoratorSink ::= DecoId args?
source ::= simpleSource
sink ::= simpleSink // single sink
| [ sink (, sink)* ] // fanout sink
| { decoratorSink => sink } // decorator sink
| decoratorSink1 decoratorSink2 ... decoratorSinkN sink // decorator sink
| < sink ? sink > // failover / choice sink
| roll(...) { sink } // roll sink
| collector(...) { sink } // generic collector sink
logicalNode ::= NodeId : source | sink ;
spec ::= (logicalNode)*Three special sinks are FanOutSinks, FailoverSinks, and RollSinks.
Fanout sinks send any incoming events to all of the sinks specified to be its
children. These can be used for data replication or for processing data off
of the main reliable data flow path. Fanout is similar to the Unix tee
command or logically acts like an AND operator where the event is sent to each
subsink.
The syntax for a FanoutSink is :
[ console, collectorSink ]
FailoverSinks are used to handle failures when appending new events. FailoverSinks can be used to specify alternate collectors to contact in the event the primary collector fails, or a local disk sink to store data until the primary collector recovers. Failover is similar to exception handling and logically acts like an OR operator. If a failover is successful, one of the subsinks has received the event.
The syntax for a FailoverSink is :
< logicalSink("collector1") ? logicalSink("collector2") >So, you could configure node "agent1" to have a failover to collector2 if
collector1 fails (for example, if the connection to collector1 goes down or
if collector1's HDFS becomes full):
agent1 : source | < logicalSink("collector1") ? logicalSink("collector2")
> ;Roll sink opens and closes a new instance of its subsink every millis milliseconds. A roll is an atomic transition that closes the current instance of the sub-sink, and then opens a new instance of as an escape sequence to differentiate data in different roll periods. This can be used to make every roll produce a new file with a unique name.
The syntax for a roll sink is:
roll(millis) sink
These can be composed to have even richer behavior. For example, this sink outputs to the console and has a failover collector node.
[ console, < logicalSink("collector1") ? logicalSink("collector2") > ]This one rolls the collector every 1000 milliseconds writing to a different HDFS file after each roll.
roll(1000) [ console, escapedCustomDfs("hdfs://namenode/flume/file-%{rolltag}") ]Fan out and failover affect where messages go in the system but do not modify the messages themselves. To augment or filter events as they pass through the dataflow, you can use sink decorators.
Sink decorators can add properties to the sink and can modify the data streams that pass through them. For example, you can use them to increase reliability via write ahead logging, increase network throughput via batching/compression, sampling, benchmarking, and even lightweight analytics.
The following simple sampling example uses an intervalSampler which is configured to send every 10th element from source "source" to the sink "sink":
flumenode: source | intervalSampler(10) sink;
| Note |
|---|---|
There is an older more verbose syntax for specifiying decorators
that wraps decorators and sinks with |
Here’s an example that batches every 100 events together.
flumenode: source | batch(100) sink;
Like fanout and failover, decorators are also composable. Here is an example that creates batches of 100 events and then compresses them before moving them off to the sink:
flumenode: source | batch(100) gzip sink;
As of v0.9.3, a new more generic collector sink that better encapsulates the "collectorMagic" functionality. This allows you to specify arbitrary sinks (or mulitple sinks) using the flume specification language. So the equivalent of
collectorSink("xxx","yyy-%{rolltag}", 15000)is now:
collector(15000) { escapedCustomDfs("xxx","yyy-%{rolltag}") }Here is an example of newly expressable functionality:
collector(15000) { [ escapedCustomDfs("xxx","yyy-%{rolltag}"), hbase("aaa", "bbb-%{rolltag}"), elasticSearch("eeee","ffff") ] }This would send data to all three destinations, and only send an ack if all three were successful. Combined with some recovery decorators (stubborn*, insistent*), this can be used to precisely express potentially complex failure recovery policies.
Internally, Flume translates sinks into compositions of other simpler decorators, failovers, rollers to add properties. The proper compositions create pipelines that provide different levels of reliability in Flume.
| Note |
|---|---|
This section describes how agents work, but this version of Flume does not expose the translations the same way the auto*Chains are exposed. A future version of Flume will expose these details. The exact translations are still under development. |
Suppose you have nodes using the different agent sinks:
node1 : tail("foo") | agentE2ESink("bar");
node2 : tail("foo") | agentDFOSink("bar");
node3 : tail("foo") | agentBESink("bar");In the translation phases, agentE2ESink is actually converted into these Flume sinks:
node1 : tail("foo") | ackedWriteAhead lazyOpen stubbornAppend logicalSink("bar") ;
node2 : tail("foo") | < lazyOpen stubbornAppend logicalSink("bar") ? diskFailover insistentOpen lazyOpen stubbornAppend logicalSink("bar") >;
node3 : tail("foo") | lazyOpen stubbornAppend logicalSink("bar");ackedWriteAhead is actually a complicated decorator that internally
uses rolls and some other special decorators. This decorator
interface allows us to manually specify wire batching and compression
options. For example, you could compress every 100 messages using
gzip compression:
node1 : tail("foo") | ackedWriteAhead batch(100) gzip lazyOpen stubbornAppend logicalSink("bar");collectorSink("xxx","yyy",15000) is also a bit complicated with some custom
decorators to handle acks. Under the covers however, it depends on a roller
with a escapedCustomDfsSink inside of it.
roll(15000) { collectorMagic escapedCustomDfs("xxx", "yyy-%{rolltag}") }Another place translations happen is with logical nodes. Lets start of with a few nodes:
node1 : tail("foo") | { .... => logicalSink("node2") };
node2 : logicalSource | collectorSink("...");The translation mechanisms converts logicalSources and logicalSinks into lower level physical rpcSources and rpcSinks. Lets assume that node1 is on machine host1 and node2 is on machine host2. After the translation you end up with the following configurations:
node1 : tail("foo") | { .... => rpcSink("host2",12345) };
node2 : rpcSource(12345) | collectorSink("..."");Suppose that you swap the mapping so that node2 is now on host1 and node1 is on host2.
# flume shell commands exec unmapAll exec map host1 node2 exec map host2 node1
The original configuration will now be translated to:
node1 : tail("foo") | { .... => rpcSink("host1",12345) };
node2 : rpcSource(12345) | collectorSink("..."");While Flume can take in raw data, you can add structure to data based on the nodes they flowed through, and filter out portions of data to minimize the amount of raw data needed if only a portion is needed.
The simplest is the value decorator. This takes two arguments: an attribute
name, and a value to add to the event’s metadata. This can be used to
annotate constant information about the source, or arbitrary data to a
particular node. It could also be used to naively track the provenance of
data through Flume.
Extraction operations are also available to extract values from logs that have known structure.
One example is the regex decorator. This takes three arguments: a regular
expression, an index, and an attribute name which allows the user to use a
extract a particular regex group out of the body of the event and write it as
the value of the specified attribute.
Similarly the split decorator also takes three arguments: a regular
expression, an index, and an attribute name. This splits the body
based on the regular expression, extracts the text group after the
instance of the separator, and writes the value to the specified
attribute. One can think of this as a much simplified version of the
awk Unix utility.
Flume enforces an invariant that prevents the modification of an attribute that has already been written upstream. This simplifies debugging of dataflows, and improves the visibility of data when debugging.
If many stages are used, however, frequently a lot of extra metadata ends up being moved around. To deal with this, a few extra operations are available.
A select operation is available. This operation is like SQL select, which
provides a relational calculus’s set projection operation that modifies an
event so that the specified metadata fields are forwarded.
A mask operation is also available that forwards all metadata attributes
except for the attributes specified.
A format decorator is also available that uses the escape mechanisms
to rewrite the body of an event to a user customizable message. This is
useful for outputting summary data to low volume sources. Example: writing
summary information out to an IRC channel periodically.
To simplify things for users, you can assign a particular role to a logical node — think of these as an "automatic" specification that have default settings. Two roles currently provided are the agent role and the collector role. Since there are many nodes with the same role, each of these are called a tier. So, for example, the agent tier consists of all the nodes that are in the agent role. Nodes that have the collector role are in the collector tier.
Agents and collectors roles have defaults specified in the conf/flume-site.xml
file. Look at the conf/flume-conf.xml file for properties prefixed with
flume.agent.\* and flume.collector.\* for descriptions of the configuration
options.
Each node maintains it own node state and has its own configuration. If the master does not have a data flow configuration for the logical node, the logical node will remain in IDLE state. If a configuration is present, the logical node will attempt to instantiate the data flow and have it work concurrently with other data flows.
This means that each machine essentially only lives in one tier. In a more complicated setup, it is possible to have a machine that contains many logical nodes, and because each of these nodes can take on different roles, the machine lives in multiple tiers.
An experimental plugin mechanism is provided that allows you to add new custom sources, sinks, and decorators to the system.
Two steps are required to use this feature.
flume-site.xml, add the class names of the new sources,
sinks, and/or decorators to the flume.plugin.classes property.
Multiple classes can be specified by comma separating the list. Java
reflection is used to find some special static methods that add new
components to the system and data flow language’s library.
An example component has been "pluginified" — the "HelloWorld" source, sink, and decorator. This plugin does something very simple; the source generates the text "hello world!" every three seconds, the sink writes events to a "helloworld.txt" text file, and the decorator prepends "hello world!" to any event it encounters.
plugins/helloworld directory and type ant, a helloworld_plugin.jar file will be generated
Add the following to flume-site.xml (create it if it doesn’t already
exist)
"helloworld.HelloWorldSink,helloworld.HelloWorldSource,helloworld.HelloWorldDecorator"
to the flume.plugin.classes property in flume-site.xml.
![[Important]](images/important.png) | Important |
|---|---|
if you use the provided |
<configuration>
<property>
<name>flume.plugin.classes</name>
<value>helloworld.HelloWorldSink,helloworld.HelloWorldSource,helloworld.HelloWorldDecorator</value>
<description>Comma separated list of plugins</description>
</property>
</configuration>Start the Flume master and at least one logical node in separate terminals
plugins
Add helloworld_plugin.jar to the FLUME_CLASSPATH in both terminals
export FLUME_CLASSPATH=`pwd`/plugins/helloworld/helloworld_plugin.jar
bin/flume master
bin/flume node -n hello1
10/07/29 17:35:28 INFO conf.SourceFactoryImpl: Found source builder helloWorldSource in helloworld.HelloWorldSource 10/07/29 17:35:28 INFO conf.SinkFactoryImpl: Found sink builder helloWorldSink in helloworld.HelloWorldSink 10/07/29 17:35:28 INFO conf.SinkFactoryImpl: Found sink decorator helloWorldDecorator in helloworld.HelloWorldDecorator
+ TIP: Another way to verify that your plugin is loaded is to check if it is displayed on this page http://localhost:35871/masterext.jsp
+ . Configure hello1
+ TIP: The easiest way to do this is open the configuration page of the master in a browser, typically this link http://localhost:35871/flumeconfig.jsp
+
.. load the helloworld source/sink into our hello1 node (the bottom text box, then submit button if you are using the master’s web interface"
+
hello1: helloWorldSource() | helloWorldSink();
you could also try the hello world decorator
hello1: helloWorldSource() | { helloWorldDecorator() => helloWorldSink() };In either case hello1 will output a helloworld.txt file into it’s current working directory. Every 3 seconds a new "hello world!" line will be output to the file.
Flume uses threading to support reconfiguration and multiple logical nodes. Sources, sinks, and decorator are extensions that can use queues for buffering and can use clock sleeps for periodic rolls and retries. Because we use these blocking operations and because the internal concurrency control mechanisms we use can cause deadlocks or hangs, there are several rules that need to be followed and enforced by test cases in order to be a well-behaved source, sink, or decorator.
| Note |
|---|---|
This section is a draft and not exhaustive or completely formal. More restrictions may be added to this in the future. |
Semantics of sources. Sources must implement 4 methods
Along with these signatures, each of these methods can also throw RuntimeExceptions. These exceptions indicate a failure condition and by default will make a logical node shutdown in ERROR state. These error messages are user visible and it is important that they have actionable descriptions about the failure conditions without having to dump stack. Thus, NullPointerExceptions are not acceptable — they are not descriptive or helpful without their stack traces.
Some examples of valid runtime exceptions include invalid arguments that prevent a source from opening and invalid state infractions (attempting to next on a closed source).
Simple sources are assumed to be sources whose open and close operation happen quickly and do not block for long periods of time. The longest pauses tolerated here on the order of 10s (default time for a failing DNS lookup).
The constructor for the sources should be callable without grabbing resources that can block or that require IO such as network connectors or file handles. If there are errors due to configuration settings that can be caught in the constructor, an IllegalArgumentException should be thrown.
open() is a call that grabs resources for the source so that the
next() call can be made. The open call of a simple source should
attempt to fail fast. It can throw a IOException or a RuntimeException
such as IllegalStateException. Open should only be called on a CLOSED
sink — if a sink is opened twice, the second call should throw an
IOException or IllegalStateException.
next() is a call that gets an event from an open source. If a
source is not open, this should throw an IllegalStateException. This
call can and will often block. If next() is blocking, a call to
close() should unblock the next() by having it exit cleanly
returning null. Many resources such as TCP-sockets (and ideally rpc
frameworks) default to throwing an exception on blocked network reads
(like a next() call) when close()'d.
close() is a call that releases resources that the open call of a
source grabs. The close() call itself blocks until all resources
are released. This allows a subsequent open() in the same thread to
not fail due to resource contention (ex, closing a server socket on
port 12345 should not return until port 12345 is ready to be bound
again).
getReport() returns a ReportEvent. These values should be available
regardless if the node is open or closed and this call should not
block the other source by other calls (due to potential lock inversion
issues). The values retrieved are ideally atomically grabbed but this
is not required as long as no errors are caused by racy execution.
If a source is opened or closed multiple times, it is up to the source to determine if values are reset or persisted between open/close cycles.
Some sources have in memory queues or buffers stored persistently on
disk. The guiding principle here is that on close(), buffered
sources should prevent new data from entering and attempt to flush the
buffered data. Also any subordinate threads should be released before
close returns. If no progress is being made on close(), for a given
period of time (30s is the default currently) the controlling thread
will for an Thread.interrupt() call. The source should be able to
handle InterruptedExceptions and percolate interrupted status up the
returning call stack.
| Note |
|---|---|
In v0.9.1 and v0.9.2, interruptions when caught should be
handled by re-flagging the Thread’s interrupted flag (a call to
|
open() no change.
close() This call is usually made from a separate thread than the
open() or next() calls. Since this call should block until resources
are freed, it should attempt to flush its buffers before returning.
For example, so if a network source has some buffered data, the
network connection should be closed to prevent new data from entering,
and then the buffered data should be flushed. The source should be
able to handle InterruptedExceptions and percolate interrupted status
up the returning call stack and indicate an error state.
A next() call while in CLOSING state should continue pulling values
out of the buffer until it is empty. This is especially true if the
next() call is happening in the main driver thread or a subordinate
driver thread. One mechanism to get this effect is to add a special
DONE event to the queue/buffer that indicates a clean exit.
getReport() ideally includes metric information like the size of the
queues in the source, and the number of elements in the queue.
Semantics of sinks and decorators. Sinks and decorators must implement 4 methods
Along with these signatures, each of these methods can also throw RuntimeExceptions. Run-time exceptions indicate a failure condition and by default will make a logical node shutdown in ERROR state. These error messages are user visible and it is important that they have helpful descriptions about the failure conditions without having to dump stack. Thus, NullPointerExceptions are not acceptable — they are not descriptive or helpful without their stack traces.
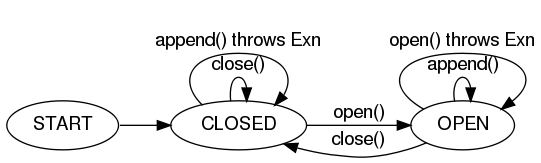
Simple sinks are assumed to have open, close, and append operations that happen quickly and do not block for long periods of time. The longest pauses tolerated here on the order of 10s (default time for a failing DNS lookup).
The constructor for the sinks and decorators should be callable without grabbing resources that can block or that require IO such as network connectors or file handles. If there are errors due to configuration settings that can be caught in the constructor, an IllegalArgumentException should be thrown.
open() is a call that grabs resources for the sink or decorator so
that the append(Event) call can be made. If there are errors due to
configuration settings not detectable without IO in the constructor,
open() should attempt to fail fast and throw a IOException or
RuntimeException such as IllegalStateException or
IllegalArgumentException. Open should only be called on a CLOSED sink — if a sink is opened twice, the second call should throw an
IOException or IllegalStateException.
append() is a call that delivers a event. If a sink is not open,
this should throw an IllegalStateException.
If a normal decorator fails to open or to append because of an internal failure or a subsink fails to open, the decorator should release its resources attempt to close the subsink and then throw an exception. There are some sink/decos that specifically manipulate these semantics — this needs to be done with care.
close() is a call that releases resources that the open call of a
source grabs. If open() or next() is blocking, a call to this
should unblock the call and have them exit. close() should be
called called on an open sink, but we allow a closed sink to have
close() called on it without throwing an exception (generally LOG
warning however).
getReport() returns a ReportEvent. These values should be available
regardless if the node is open or closed and this call should not
cause get blocked by other calls (due to potential lock inversion
issues). The values retrieved are ideally atomically grabbed but this
is not required as long as no errors are caused by racy execution. If
a sink is opened or closed multiple times, it is up to the sink to
determine if values are reset or persisted between open/close cycles.
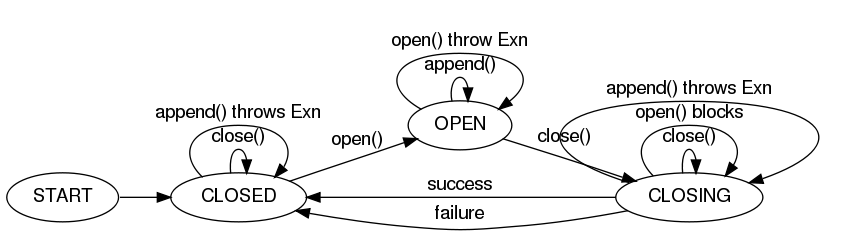
Some sinks have queues or buffers stored in memory or persistently on
disk. The guiding principle here is that buffered sinks should
attempt to flush its buffers when prompted to close(). This needs
to be balanced with the requirement that sinks and decorated sinks
should attempt to close in a relatively quick fashion.
open() Since this sink isn’t open this generally means there is no
buffered data. However, an open() on a sink or decorator with
persistent data should attempt to recover data and enqueue it in the
open() call. Examples of these include a DFO or WAL log recovering
dfo/wla logs, when a network subsink is down.
An append() call may buffer data before sending it (such as a
batching decorator). A close() call, should attempt to append
buffered data to its (sub)sink before executing the close. Also, any
subordinate threads should be stopped before shutdown.
If no progress is being made on close(), for a given period of time
(30s is the default currently) it will be interrupted and should
handle abruptly exiting because of this interruption.
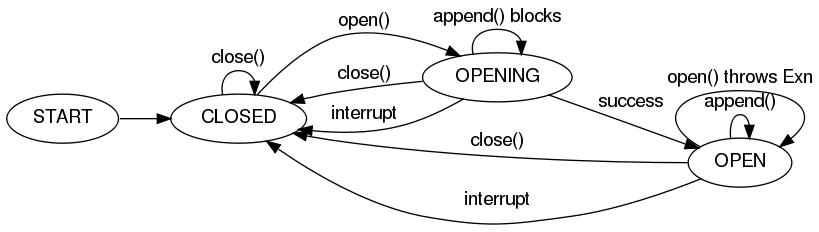
Retry on open semantics
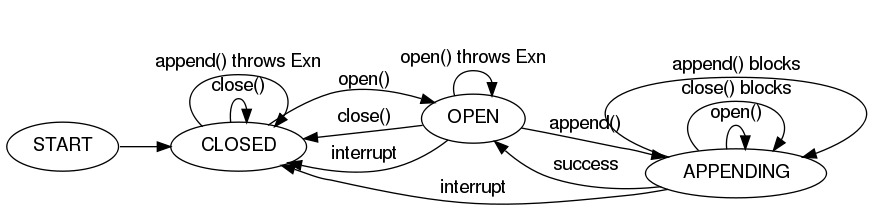
Retry on Append semantics
Some decorators introduce retries and sleeps. An author who uses these needs to ensure that these operations behave well on open, append, and close. When combined with buffering sinks, flushing a buffer on close may not be possible! (ex: wal trying to send data to a dead network connection). This means these sinks/decos need a way to exit abruptly and report an error. There are two operations that make these cases need to be handled: unbounded retries and unbounded/long sleeps/await/blocking.
Some decorators have potentially unbounded retry semantics. For
example, InsistentOpen, InsistentAppend, and FailoverSinks have the
potential to retry open() and append() calls an unbounded number
of times. These decorators can also be wrapped with in others — this
means we need to be able to percolate the hard exit and bypass the
retry logic.
To do this we require that any sink/deco that has retry logic must check for hard exit before retrying. These sinks must to propagate the hard exit interruption to its upstream decorators (in case they have retry logic!).
Some sinks have the potential to backoff or sleep for long or
potentially unbounded amounts of time. Code using sleeps or
synchronization operations such as waiting on latches
(CountDownLatch.await()) or thread sleeps (Thread.sleep()) must
properly handle interruptions. Since these yielding operations are
usually only used in retry operations (which meant there was a
failure), the sink/deco needs to propagate the interruption and fail
with error.
There are some ramifications of these semantics. Care must be taken
with locking open, close, and append operations. If there are any
sleeps or blocking open() operations (ex: InsistentOpen,
FailoverSinks), ideally a close call will cause it to shutdown, it and
the open call should get unblocked. append()
The sink signaled to be closed but blocked on append() or open()
should exit in a reasonable amount of time — ideally within a few
heartbeats (5s is the default, so ideally <30s). If the sink exits
and its buffers are empty, it should do a normal successful return.
If there were unflushed events, it should return error by throwing an
exception. If there are subordinate threads, these should be
terminated before close returns.
Flume has the ability to limit the rate of transfer of data between source-sink pairs. This is useful to divide the network bandwidth non-uniformly among different source-sink pairs based on the kind of logs they are transferring. For example, you can ship some types of logs at a faster rate than others, or you can transfer logs at different rates at different times of the day.
Another example of when it is beneficial to limit the rate of data transfer is when the network (or a collector) recovers after a failure. In this case, the agents might have a lot of data backed up to ship; if there is no limit on the transfer rate, the agents can exhaust all of the resources of the collector and possibly cause it to crash.
In Flume, you can use a special sink-decorator called the choke decorator to limit the rate of transfer of data between source-sink pairs.
Each choke decorator (called a choke) has to be assigned to a choke-id.
Here is an example of using a choke between a source and sink of a node; the choke-id of this choke is "Cid".
node: source | { choke("Cid") => sink };The choke-ids are specific to a physical node. Before using a choke on node,
you must register the choke-id on the physical node containing the node.
You can register a choke-id on a physical node using the setChokeLimit command.
When registering a choke-id, you must also assign a rate limit (in KB/sec) to it.
Here is an example of registering a choke-id "Cid" on a physical node host and assigning a limit 1000 KB/sec.
exec setChokeLimit host Cid 1000
| Note |
|---|---|
You can also use setChokeLimit at the run-time to change the limit assigned to a |
The limit on the choke-id specifies an upper bound on the rate at which the chokes using that choke-id can collectively transfer data.
In the preceding example, there is only one source-sink pair on the physical node host that uses a choke with choke-id "Cid". Consequently, the rate of data transfer between that source-sink pair is limited to 1000 KB/sec.
| Note |
|---|---|
For the purpose of rate limiting, only the size of the event body is taken into account. |
The choke decorator works as follows: when append() is called on the sink to which the choke
is attached, the append() call works normally if the amount of data transferred
(during a small duration of time) is within the limit assigned to the choke-id corresponding to the choke.
If the limit has been exceeded, then append() is blocked for a small duration of time.
Suppose there are multiple source-sink pairs using chokes between them, and they are using
the same choke-id. Suppose further that both node1 and node2 are logical nodes on the same physical node host,
and a choke-id "Cid" with limit 1000KB/sec is registered on host.
node1: source1 | { choke("Cid") => sink1 };
node2: source2 | { choke("Cid") => sink2 };In this example, because both source1-sink1 and source2-sink2 pairs are using chokes with the same choke-id "Cid", the total data going across these source-sink pairs collectively is limited to 1000KB/sec.
Flume does not control how this limit will be divided between the source-sink pairs,
but it does guarantee that neither source-sink pair will starve.
| Note |
|---|---|
If multiple source-sink pairs on the same physical node use chokes that have the same choke-id, then there is no guarantee how the rate limit will be divided between these source-sink pairs. |
| Note |
|---|---|
This section is only required if you are using a Kerberized HDFS cluster. If you are running CDH3b2 or a Hadoop version 0.21.x or earlier, you can safely skip this section. |
Flume’s datapath needs to be able to interact with "secured" Hadoop and HDFS. The Hadoop and HDFS designers have chosen to use the Kerberos V5 system and protocols to authenticate communications between clients and services. Hadoop clients include users, MR jobs on behalf of users, and services include HDFS, MapReduce.
In this section we will describe how setup up a Flume node to be a client as user flume to a kerberized HDFS service. This section will not talk about securing the communications between Flume nodes and Flume masters, or the communications between Flume nodes in a Flume flow. The current implementation does not support writing individual isolated flows as different users.
| Note |
|---|---|
This has only been tested with the security enhanced betas of CDH (CDH3b3+), and the MIT Kerberos 5 implementation. |
Flume will act as a particular Kerberos principal (user) and needs credentials. The Kerberos credentials are needed in order to interact with the kerberized service.
There are two ways you can get credentials. The first is used by interactive users because it requires an interactive logon. The second is generally used by services (like a Flume daemon) and uses a specially protected key table file called a keytab.
Interactively using the kinit program to contact the Kerberos KDC
(key distribution center) is one way is to prove your identity. This
approach requires a user to enter a password. To do this you need a
two part principal setup in the KDC, which is generally of the form
user@REALM.COM. Logging in via kinit will grant a ticket granting
ticket (TGT) which can be used to authenticate with other services.
| Note |
|---|---|
this user needs to have an account on the namenode machine as well — Hadoop uses this user and group information from that machine when authorizing access. |
Authenticating a user or a service can alternately be done using a specially protected keytab file. This file contains a ticket generating ticket (TGT) which is used to mutually authenticate the client and the service via the Kerberos KDC.
| Note |
|---|---|
The keytab approach is similar to an "password-less" ssh connections. In this case instead of an id_rsa private key file, the service has a keytab entry with its private key. |
Because a Flume node daemon is usually started unattended (via service
script), it needs to login using the keytab approach. When using a
keytab, the Hadoop services requires a three part principal. This has
the form user/host.com@REALM.COM. We recommend using flume as the
user and the hostname of the machine as the service. Assuming that
Kerberos and kerberized Hadoop has been properly setup, you just need
to a few parameters to the Flume node’s property file
(flume-site.xml).
<property> <name>flume.kerberos.user</name> <value>flume/host1.com@REALM.COM </value> <description></description> </property> <property> <name>flume.kerberos.keytab</name> <value>/etc/flume/conf/keytab.krb5 </value> <description></description> </property>
In this case, flume is the user, host1.com is the service, and
REALM.COM is the Kerberos realm. The /etc/keytab.krb5 file contains
the keys necessary for flume/host1.com@REALM.COM to authenticate
with other services.
Flume and Hadoop provides a simple keyword (_HOST) that gets expanded to be the host name of the machine the service is running on. This allows you to have one flume-site.xml file with the same flume.kerberos.user property on all of your machines.
<property> <name>flume.kerberos.user</name> <value>flume/_HOST@REALM.COM </value> <description></description> </property>
You can test to see if your Flume node is properly setup by running the following command.
flume node_nowatch -1 -n dump -c 'dump: console | collectorSink("hdfs://kerb-nn/user/flume/%Y%m%D-%H/","testkerb");'This should write data entered at the console to a kerberized HDFS
with a namenode named kerb-nn, into a /user/flume/YYmmDD-HH/
directory.
If this fails, you many need to check to see if Flume’s Hadoop settings (in core-site.xml and hdfs-site.xml) are using Hadoop’s settings correctly.
| Note |
|---|---|
These instructions are for MIT Kerb5. |
There are several requirements to have a "properly setup" Kerberos HDFS + Flume.
Much of this setup can be done by using the kadmin program, and
verified using the kinit, kdestroy, and klist programs.
First you need to have permissions to use the kadmin program and the
ability to add to principals to the KDCs.
$ kadmin -p <adminuser> -w <password>
If you entered this correctly, it will drop you do the kadmin prompt
kadmin:
Here you can add a Flume principal to the KDC
kadmin: addprinc flume WARNING: no policy specified for flume@REALM.COM; defaulting to no policy Enter password for principal "flume@REALM.COM": Re-enter password for principal "flume@REALM.COM": Principal "flume@REALM.COM" created. kadmin:
You also need to add principals with hosts for each Flume node that will directly write to HDFS. Since you will be exporting the key to a keytab file, you can use the -randkey option to generate a random key.
kadmin: addprinc -randkey flume/host.com WARNING: no policy specified for flume/host.com@REALM.COM; defaulting to no policy Principal "flume/host.com@REALM.COM" created. kadmin:
| Note |
|---|---|
Hadoop’s Kerberos implementation requires a three part principal name — user/host@REALM.COM. As a user you usually only need the user name, user@REALM.COM. |
You can verify that the user has been added by using the kinit
program, and entering the password you selected. Next you can verify
that you have your Ticket Granting Ticket (TGT) loaded.
$ kinit flume/host.com Password for flume/host.com@REALM.COM: $ klist Ticket cache: FILE:/tmp/krb5cc_1016 Default principal: flume/host.com@REALM Valid starting Expires Service principal 09/02/10 18:59:38 09/03/10 18:59:38 krbtgt/REALM.COM@REALM.COM Kerberos 4 ticket cache: /tmp/tkt1016 klist: You have no tickets cached $
You can ignore the Kerberos 4 info. To "logout" you can use the
kdestroy command, and then verify that credentials are gone by
running klist.
$ kdestroy $ klist klist: No credentials cache found (ticket cache FILE:/tmp/krb5cc_1016) Kerberos 4 ticket cache: /tmp/tkt1016 klist: You have no tickets cached $
Next to enable automatic logins, we can create a keytab file so that does not require manually entering a password.
| Warning |
|---|---|
This keytab file contains secret credentials that should be protected so that only the proper user can read the file. After created, it should be in 0400 mode (-r--------) and owned by the user running the Flume process. |
Then you can generate a keytab file (int this example called
flume.keytab) and add a user flume/host.com to it.
kadmin: ktadd -k flume.keytab flume/host.com
| Note |
|---|---|
This will invalidate the ability for flume/host.com to manually login of the account. You could however have a Flume user does not use a keytab and that could log in. |
| Warning |
|---|---|
|
You can verify the names and the version (KVNO) of the keys by running the following command.
$ klist -Kk flume.keytab Keytab name: FILE:flume.keytab KVNO Principal ---- -------------------------------------------------------------------------- 5 flume/host.com@REALM.COM (0xaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa) 5 flume/host.com@REALM.COM (0xbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb) 5 flume/host.com@REALM.COM (0xcccccccccccccccc) 5 flume/host.com@REALM.COM (0xdddddddddddddddd)
You should see a few entries and your corresponding keys in hex after your principal names.
Finally, you can use kinit with the flume@REALM.COM principal to
interactively do a Kerberos login and use the Hadoop commands to browse HDFS.
$ kinit flume Password for flume@REALM.COM: <-- enter password $ hadoop dfs -ls /user/flume/
Flume’s Tiered Event Sources. These sources and sinks are actually translated from their original specification into compositions of more specific lower level configurations. They generally have reasonable default arguments assigned by the properties xml file or by the Master. The defaults can be overridden by the users.
|
|
Collector source. Listens for data from
agentSinks forwarding to port |
|
|
Auto collector source. Creates a logical collector that, when assigned to a physical node, will be included in the list of collectors in a failover chain. This is the collector counterpart to auto*Chain() sinks. See the section Automatic Failover Chains for additional information. |
|
|
Logical Source. This source has a port assigned to it by the Master and listens for rpcSink formatted data. |
Flume’s Basic Sources. These sources are untranslated and generally need all of their arguments.
|
|
Null source. Opens, closes, and returns null (last record) on next(). |
|
|
Stdin console source. This is for inputting events as an
interactive user and provides features such as edit history and
keyboard edit shortcuts. A flume node must be started with the |
|
|
Stdin source. This is for piping data into a flume node’s
standard input data source. A flume node must be started with the
|
|
|
A remote procedure call (RPC) server that is
configured to listen on TCP port |
|
|
One-time text file source. One event per |
tail("filename"[, startFromEnd=false]{,delim="regex",
delimMode="exclude|prev|next"}) :: Similar to Unix’s tail
utility. One line is one event. Generates events for the entire file
then stays open for more data, and follows filename. (e.g. if tailing
file "foo" and then "foo" is moved to "bar" and a new file appears
named "foo", it will finish reading the new "bar" file and then start
from the beginning of "foo"). If the startFromEnd parameter is
false, tail will re-read from the beginning of the file. If it is
true, it will only start reading from the current end of file. If the
last line of a file does not end with a newline character (\n), the
tail source will only send an event with this last line when the
tail is closed. See the section on tailing a file for details on
delim and delimMode.
multitail("filename"[, file2 [,file3 … ] ])
tail but can
follow multiple files concurrently.
tailDir("dirname"[, fileregex=".*"[, startFromEnd=false[,
recurseDepth=0]]]{,delim="regex", delimMode="exclude|prev|next"})
:: Tails all files in a directory dirname that match the specified
fileregex. Be careful and make sure because the regex argument
requires java style escaping of \ and \". For example \w+ would
have to be written as "\\w+". If a new file appears, it is added to
the list of files to tail. If pointed at a new directory, it will
attempt to read all files that match! If the startFromEnd parameter
is false, tail will re-read from the beginning of each file. If it is
true, it will only start reading from the current end of each file.
If the recurseDepth parameter is > 0 then tailDir will recurse into
sub-directories. The value defines max level of a directory below the
dirname to tail files in. Zero means do not recurse into
sub-directories. Note: fileregex is applied to file names only (not
including dirs), all directories (which fit recurseDepth parameter)
are recursed into. See the section on tailing a file for details on
delim and delimMode.
seqfile("filename")
com.cloudera.flume.handlers.hdfs.WriteableEventKey and
com.cloudera.flume.handlers.hdfs.WriteableEvent values. Conveniently, this
source can read files generated by the seqfile sink.
syslogUdp(port)
port. This is syslog compatible.
syslogTcp(port)
port. This is syslog-ng compatible.
This is a server that can listen and receive on many concurrent connections.
syslogTcp1(port)
port. This is syslog-ng
compatible. This is only available for a single connection and then shuts
down afterwards.
execPeriodic("cmdline", ms)
cmdline. The entire output of the execution becomes
the body of generated messages. ms specifies the number of
milliseconds to wait before the next execution (and next
event). Ideally the program is short lived. This does not process
shell pipes or redirection operations — for these write a script and
use the script as the cmdline argument.
execStream("cmdline")
cmdline. Each line outputted will become a new event. Ideally
the program is long lived. This does not process shell pipes or
redirection operations — for these write a script and use the script
as the cmdline argument.
exec("cmdline"[, aggregate=false[, restart=false[,period=0]]])
cmdline. If the aggregate
argument is true entire program output is considered an event; otherwise,
each line is considered a new event. If the restart argument is true,
then the program is restarted after it exits after waiting for period
milliseconds. execStream("foo") is equivalent to exec("foo", false, false,
0). execPeriodic("foo", 1000) is equivalent to exec("foo", true, true,
1000)
synth(msgCount,msgSize)
msgCount random messages of size msgSize. This will generate non
printable characters.
synthrndsize(msgCount,minSize,maxSize)
msgCount random messages of size between randomly minSize and maxSize.
This will generate non printable characters.
nonlsynth(msgCount,msgSize)
msgCount random messages of size msgSize. This converts all '\n'
chars into ' ' chars. This will generate non-printable characters but since
all randomly generated \n are converted, sources dependent on \n as a
record separator can get uniformly sized data.
asciisynth(msgCount,msgSize)
msgCount random messages of size msgSize. This converts all '\n'
chars into ' ' chars, and all non ASCII characters into printable ASCII
characters.
twitter("username","pw"[,"url"])
username is a twitter
username, pw is the password for the user, and url is the url for the
feed. If not specified, http://stream.twitter.com/1/statuses/sample.json is
used by default the url. See http://apiwiki.twitter.com/Streaming-API-
Documentation for more details.
irc("server",port, "nick","chan")
server on TCP port port (standard is 6667). When it connects it
attempts to take the nickname nick, and enter channel chan (like
#hadoop ).
scribe[(+port)]
report[(periodMillis)]
Table 4. Flume’s Collector Tier Event Sinks
|
|
Collector sink.
|
Table 5. Flume’s Agent Tier Event Sinks
|
|
Defaults to |
|
|
Agent sink with write ahead log and
end-to-end ack. Optional arguments specify a |
|
|
DiskFailover Agent sink that stores
to local disk on detected failure. This sink periodically checks with the
|
|
|
BestEffort Agent sink. This drops
messages on failures and continues sending. Optional arguments specify a
|
|
|
Agent sink
with write-ahead log and end-to-end ack and collector failover
chains. |
|
|
DiskFailover
Agent sink that first attempts to fail over to other
collectors. |
|
|
BestEffort
Agent sink with collector failover chains. |
|
|
This sink is an |
|
|
This sink is an |
|
|
This sink is an |
Flume’s Logical Sinks
logicalSink("logicalnode")
Table 6. Flume’s Basic Sinks
|
|
Null sink. Events are dropped |
|
|
Console sink. Display events to process’s stdout using the optionally specified output formatter. |
|
|
Textfile sink. Write to text file
txtfile, using an optionally specified |
|
|
Seqfile sink. Write to a Hadoop sequence file
formatted file, with |
|
|
Hadoop dfs seqfile sink. Write to a dfs path
in Flume- specific Hadoop seqfile record format. The |
|
|
Hadoop dfs formatted file sink. The hdfspath string is not escaped. The output format of writes to a dfs path in using specified output format. |
|
+escapedFormatDfs("hdfspath", "file"[, format]) |
Hadoop dfs formatted
file sink. The hdfspath string is escaped and events will get written to
particular directories and filenames based on this string. The output format
of writes to a dfs path in using specified output format. The |
|
|
Hadoop dfs formatted file
sink. The hdfspath string is not escaped. The output format of
writes to a dfs path in using specified output format. This sink is
being deprecated by |
|
+escapedCustomDfs("hdfspath", "file"[, format]) |
Hadoop dfs
formatted file sink. The hdfspath string is escaped and events will
get written to particular directories and filenames based on this
string. The output format of writes to a dfs path in using specified
output format. The |
|
|
A remote procedure call (RPC) sink that is
configured to send to machine |
|
|
Syslog TCP sink. Write to host "host" on port "port" in syslog over TCP format (syslog-ng compatible). Default port is TCP 514. |
|
|
(Unsupported) An IRC channel
sink. Each event is sent to the channel as a line. It attempts to connect to
|
Table 7. Flume’s Sink Decorators
|
|
This is a decorator that just passes data through to its child sink. |
|
|
Write-ahead decorator. Provides durability by writing events to disk before sending them. This can be used as a buffering mechanism — receive and send are decoupled in different threads. |
|
|
Write-ahead decorator that adds
acknowledgement tags and checksums to events. Provides durability by writing
events to disk before sending them. This can be used as a buffering mechanism — receive and send are decoupled in different threads. This generates and
tracks groups of events, and also notifies other components to check for
acknowledgements. These checks for retries are done where there is an
exponential backoff that can top out at maxmillis milliseconds. The default
value for maxmillis is |
|
|
Disk failover decorator. Events that enter
this decorator are sent to its sub sink. In the event of a down stream error,
data is written to disk, and periodically these disk-buffered events are
retried. These checks for retries are done where there is an exponential
backoff that can top out at maxmillis milliseconds. The default value for
maxmillis is |
|
|
This decorator injects an extra ack group start message on
open, tags appended events with an ack tag, and injects an extra ack group end
message. These tags contain a checksum, for all the bodies of the events that
pass through the |
|
|
This decorator tracks ack group start, end, and checksum
values inserted by |
|
|
This decorator tracks open/closed state of the sub sink but does not actually open the sink until an append is called. Thus if a this decorator is opened and closed without any appends, the sub sink is never opened. |
|
|
An insistent open attempts to open its subsink multiple times until it succeeds with the specified backoff properties. This is useful for starting a network client up when the network server may not yet be up. When an attempt to open the subsink fails, this exponentially backs off and then retries the open. max is the max number of millis per backoff (default is Integer.MAX_VALUE). init is the initial number of millis to back off on the first encountered failure (default 1000). cumulativeMax is the maximum backoff allowed from a single failure before an exception is forwarded (default is Integer.MAX_VALUE). Note that this synchronously blocks the open call until the open succeeds or fails after cumulativeMax millis. |
|
|
A stubborn append normally passes through append operations to its subsink. It catches the first exception that a subsink’s append method triggers, and then closes, opens, and reappends to the subsink. If this second attempt fails, it throws an exception. This is useful in conjunction with network sinks where connections can be broken. The open/ close retry attempt is often sufficient to re-establish the connection. |
|
|
The value decorator adds a new metadata attribute attr with the value value. Agents can mark their data with specific tags for later demultiplexing. By default a value the user entered will be attached. By setting escape=true, the value will be interpreted and attempt to replace escape sequences with values from the event’s attribute list. |
|
|
The mask decorator outputs inputted events that are modified so that all metadata except the attributes specified pass through. |
|
|
The select decorator outputs inputted events that are modified so that only the metadata attributes specified pass through. |
|
|
The digest decorator
calculates a message digest of the event body and writes this value (as bytes)
to the attr attribute. The valid algorithms are those valid for
|
|
|
The format decorator outputs inputted events that are
modified so that their bodies are replaced with an escaped version of the
|
|
|
Parse a date string from the attr value of the event, using the pattern as a reference of how to parse it. The major values of the date will be assigned to new event attributes using "date" as a prefix if no prefix is provided. To add or remove zero padding there is the padding variable. By default zero padding is on. Example of zero padding 2010-1-1 becomes 2010-01-01. More info on how to construct the pattern can be found here http://download-llnw.oracle.com/javase/1.4.2/docs/api/java/text/SimpleDateFormat.html Do note that attr is an already extracted date string from the body of the event. exDate doesn’t attempt to extract it from the body for you. Example output attributes would be dateday, datemonth, dateyear, datehr, datemin, datesec. Where date is the prefix. |
|
|
The regex decorator applies the regular
expression regex, extracts the idx th capture group, and writes this value
to the attr attribute. The regex must use java-style escaping. Thus a
regexs that want to use the |
|
regexAll("regex", "name" [, "name"]*)+ |
Applies the regular expression regex to the event body, and assignes all pattern groups found to each provided name. |
|
|
The split decorator uses the
regular expression regex to split the body into tokens (not
including the splitter value). The idx is then written as the value
to the attr attribute. The regex must use java-style escaping.
Thus, a regex that wants to use the |
|
|
buffers n events and then sends one aggregate event. If maxlatency millis have passed, all current buffered events are sent out as an aggregate event. |
|
|
Unbatch takes an aggregate event generated by batch, splits it, and then forwards its original events. If an event is not an aggregate it is just forwarded. |
|
|
gzips a serialized event. This is useful when used in conjunction with aggregate events. |
|
|
gunzip’s a gzip’ed event. If the event is not a gzip event, it is just forwarded. |
|
|
Interval sampler. Every |
|
|
Probability sampler. Every event has a probability p (where 0.0 ≤ p ≤ 1.0) chance of being forwarded. |
|
|
Reservoir sampler. When flushed, at most k events are forwarded. If more than k elements have entered this decorator, exactly k events are forwarded. All events that pass through have the same probability of being selected. NOTE: This will reorder the events being sent. |
|
|
adds a ms millisecond delay before forwarding events down
the pipeline. This blocks and prevents other events from entering the
pipeline. This is useful for workload simulation in conjunction with
|
|
|
Limits the transfer rate of data going into the sink.
The |
This section describes several environment variables that affect how
Flume operates. The flume script in ./bin uses these system
environment variables. Many of these variables are set by the
flume-daemon.sh script used when flume is run as a daemon.
|
|
The directory where a flume node or flume master will drop pid files corresponding to the daemon process. |
|
|
The custom java classpath environment variable
additions you want flume to run with. These values are prepended to
the normal Flume generated CLASSPATH. WARNING: The |
|
|
The directory where debugging logs generated by the flume node or flume master are written. |
|
|
This sets the suffix for the logfiles generated by flume node or flume master. |
|
|
The log4j logging setting for the executing command. By default it is "INFO,console". |
|
|
The log4j logging setting for a master’s embedded zookeeper server’s logs. By default it is "ERROR,console". |
|
|
The log4j logging setting for the logging the watchdog that wraps flume nodes and flume masters generates. By default it is "INFO,console". |
|
|
The directory where the |
|
|
The directory where Hadoop jars are expected to be
found. If not specified it will use jars found in |
|
|
If this value is set to "true" the |
|
|
If it this is toggled, the flume script will print out the command line being executed. |
|
|
If this is toggled along with FLUME_VERBOSE, the "-verbose" flag will be passed to the JVM running flume. |
|
|
Populate with a : separated list of file paths to extend the java.library.path aspect of Flume. This allows you to include native libraries in the java lookup path. Example usage would be with Lzo where you need to extend the path with the Lzo C libraries contained in your Hadoop install. |
TCP ports are used in all situations.
node collector port |
| 35853+ |
node status web server |
| 35862+ |
master status web server |
| 35871 |
master heartbeat port |
| 35872 |
master admin/shell port |
| 35873 |
master gossip port |
| 57890 |
master report port |
| 45678 |
master → zk port |
| 3181 |
zk → zk quorum port |
| 3182 |
zk → zk election port |
| 3183 |
When using auto chains for collectors, each collector source will
automatically search for a free port by incrementing starting from
port flume.collector.port and incrementing the port number.
When there is more than one physical node on a machine, the node
status web server will attempt to bind to port flume.node.http.port.
If the bind fails, the port number will be incremented and the bind
retried until a free port is found. The port that is eventually bound
to is logged.
Currently, there are constraints writing to HDFS. A Flume node can only write to one version of Hadoop. Although Hadoop’s HDFS API has been fairly stable, HDFS clients are only guaranteed to be wire compatible with the same major version of HDFS. Cloudera’s testing used Hadoop HDFS 0.20.x and HDFS 0.18.x. They are API compatible so all that is necessary to switch versions is to swap out the Hadoop jar and restart the node that will write to the other Hadoop version.
You still need to configure this instance of Hadoop so that it talks to the
correct HDFS nameNode. You configure the Hadoop client settings (such as
pointers to the name node) the same way as with Hadoop dataNodes or worker
nodes — modify and use conf/core-site.xml.
By default, Flume checks for a Hadoop jar in /usr/lib/hadoop. If it is not
present, it defaults to a jar found in its own lib directory, /usr/lib/flume/
lib.
If a node does not show up on the Master, you should first check to see if the node is running.
# jps | grep FlumeNode
You can also check logs found in /usr/lib/flume/logs/flume-flume-node*.log.
Common errors are error messages or warnings about being unable to contact the masters. This could be due to host misconfiguration, port misconfiguration (35872 is the default heartbeat port), or fire walling problems.
Another possible error is to have a permissions problems with the local
machine’s write-ahead log directory. On an out-of-the-box setup, this is in
the /tmp/flume/agent directory). If a Flume Node is ever run as a user
other than flume, (especially if it was run as root), the directory needs
to be either deleted or its contents must have its permissions modified to
allow Flume to use it.
Nodes by default start and choose their hostname as their physical node
name. Physical nodes names are supposed to be unique. Unexpected results may
occur if multiple physical nodes are assigned the same name.
On Ubuntu-based installations, logs are written to /usr/lib/logs/.
/usr/lib/logs/flume-flume-master-host.log
/usr/lib/logs/flume-flume-master-host.out.*
/usr/lib/ logs/flume-flume-node-host.log
/usr/lib/logs/flume-flume- node-host.out.*
There are two limits in Linux — the max number of allowable open files (328838), and max number of allowable open files for a user (default 1024). Sockets are file handles so this limits the number of open TCP connections available.
On Ubuntu, need to add a line to /etc/security/limits.conf
<user> hard nofile 10000
The user should also add the following line to a ~/.bash_profile to raise
the limit to the hard limit.
ulimit -n 10000
Flume currently relies on the file system for logging mechanisms. You must make sure that the user running Flume has permissions to write to the specified logging directory.
Currently the default is to write to /tmp/flume. In a production system you should write to a directory that does not automatically get deleted on reboot.
Yes. In the collector sink or dfs sinks you can use the s3n:// or s3://
prefixes to write to S3 buckets.
First you must add some jars to your CLASSPATH in order to support s3 writing. Here is a set that Cloudera has tested (other versions will likely work as well):
s3n uses the native s3 file system and has some limitations on individual
file sizes. Files written with this method are compatible with other programs
like s3cmd.
s3 writes using an overlay file system must go through Hadoop for file
system interaction.
First commit. design, experimental implementations. Initial implementation had individual agent and collector programs, watchdog
______
/ ___//_ ______ ____
/ /_/ / / / / \/ __/
/ __/ / /_/ / / / / __/
/ / /_/\____/_/_/_/\__/
/_/ Distributed Log Collection.